L’entreprise moyenne a radicalement changé au cours de la dernière décennie.
Que ce soit l’équipement utilisé aux bureaux ou le logiciel utilisé pour communiquer, très peu de choses se ressemblent comme avant.
Une autre chose qui est complètement différente est la quantité de données que nous avons à portée de main. Ce qui était autrefois rare est maintenant une quantité apparemment écrasante de données. Mais ce n’est accablant que si vous ne savez pas comment analyser les données de votre entreprise pour trouver une signification vraie et perspicace.
Alors, comment allez-vous du point A, ayant une grande quantité de données, au point B, en étant capable d’interpréter avec précision ces données? Tout se résume à utiliser les bonnes méthodes d’analyse statistique, c’est-à-dire la façon dont nous traitons et collectons des échantillons de données pour découvrir des modèles et des tendances.
Pour cette analyse, il y en a cinq au choix: moyenne, écart-type, régression, test d’hypothèse et détermination de la taille de l’échantillon.
Les 5 méthodes d’analyse statistique
On ne peut nier que le monde devient obsédé par le big Data, que vous soyez un data scientist ou non. Pour cette raison, vous devez savoir par où commencer. Ces cinq méthodes sont basiques, mais efficaces, pour parvenir à des conclusions précises fondées sur des données.
Moyenne
La première méthode utilisée pour effectuer l’analyse statistique est la moyenne, plus communément appelée moyenne. Lorsque vous cherchez à calculer la moyenne, vous additionnez une liste de nombres, puis divisez ce nombre par les éléments de la liste.
Lorsque cette méthode est utilisée, elle permet de déterminer la tendance globale d’un ensemble de données, ainsi que la possibilité d’obtenir une vue rapide et concise des données. Les utilisateurs de cette méthode bénéficient également du calcul simpliste et rapide.
La moyenne statistique vient avec le point central des données en cours de traitement. Le résultat est appelé la moyenne des données fournies. Dans la vraie vie, les gens utilisent généralement des moyens en ce qui concerne la recherche, les universitaires et les sports. Pensez au nombre de fois où la moyenne au bâton d’un joueur est discutée au baseball; c’est leur moyenne.
Comment trouver la moyenne
Pour trouver la moyenne de vos données, vous devez d’abord additionner les nombres, puis diviser la somme par le nombre de nombres dans l’ensemble de données ou la liste.
Par exemple, pour trouver la moyenne de 6, 18 et 24, vous devez d’abord les additionner.
6 + 18 + 24 = 48
Ensuite, divisez par le nombre de nombres dans la liste (3).
48 / 3 = 16
La moyenne est de 16.
L’inconvénient
Lorsque l’utilisation de la moyenne est excellente, elle n’est pas recommandée comme méthode d’analyse statistique autonome. En effet, cela peut potentiellement ruiner les efforts complets derrière le calcul, car il est également lié au mode (la valeur qui se produit le plus souvent) et à la médiane (le milieu) dans certains ensembles de données.
Lorsque vous traitez un grand nombre de points de données avec un nombre élevé de valeurs aberrantes (un point de données qui diffère considérablement des autres) ou une distribution inexacte des données, la moyenne ne donne pas les résultats les plus précis dans l’analyse statistique pour une décision spécifique.
Écart type
L’écart type est une méthode d’analyse statistique qui mesure la propagation des données autour de la moyenne.
Lorsque vous avez affaire à un écart-type élevé, cela indique des données largement réparties par rapport à la moyenne. De même, un écart faible montre que la plupart des données sont conformes à la moyenne et peuvent également être appelées la valeur attendue d’un ensemble.
L’écart type est principalement utilisé lorsque vous devez déterminer la dispersion des points de données (qu’ils soient ou non en cluster).
Disons que vous êtes un spécialiste du marketing qui a récemment mené une enquête auprès des clients. Une fois que vous obtenez les résultats de l’enquête, vous souhaitez mesurer la fiabilité des réponses afin de prédire si un plus grand groupe de clients pourrait avoir les mêmes réponses. Si un écart-type faible se produit, cela montrerait que les réponses peuvent être projetées à un plus grand groupe de clients.
En savoir plus : Le clustering est une technique d’exploration de données qui regroupe de grandes quantités de données en fonction de leurs similitudes.
Comment trouver l’écart-type
La formule pour calculer l’écart-type est:
σ2 = Σ(x−μ)2 / n
Dans cette formule:
- Le symbole de l’écart-type est σ
- Σ représente la somme des données
- x représente la valeur de l’ensemble de données
- μ représente la moyenne des données
- σ2 représente la variance
- n représente le nombre de points de données dans le la population
Pour trouver l’écart type:
- Trouvez la moyenne des nombres dans l’ensemble de données
- Pour chaque nombre dans l’ensemble de données, soustrayez la moyenne et quadrez le résultat (qui est cette partie de la formule (x−μ) 2).
- Trouvez la moyenne de ces différences au carré
- Prenez la racine carrée de la réponse finale
Si vous utilisiez les trois mêmes nombres dans notre exemple moyen, 6, 18 et 24, l’écart type, ou σ, serait 7,4833147735479.
L’inconvénient
Sur une note similaire à l’inconvénient de l’utilisation de la moyenne, l’écart-type peut être trompeur lorsqu’il est utilisé comme seule méthode dans votre analyse statistique.
Par exemple, si les données avec lesquelles vous travaillez ont trop de valeurs aberrantes ou un motif étrange comme une courbe non normale, l’écart-type ne fournira pas les informations nécessaires pour prendre une décision éclairée.
Régression
En matière de statistiques, la régression est la relation entre une variable dépendante (les données que vous cherchez à mesurer) et une variable indépendante (les données utilisées pour prédire la variable dépendante).
Cela peut également s’expliquer par la façon dont une variable affecte une autre, ou par des changements dans une variable qui déclenchent des changements dans une autre, essentiellement de cause à effet. Cela implique que le résultat dépend d’une ou plusieurs variables.
La ligne utilisée dans les graphiques et les tableaux d’analyse de régression indique si les relations entre les variables sont fortes ou faibles, en plus de montrer des tendances sur une période de temps spécifique.
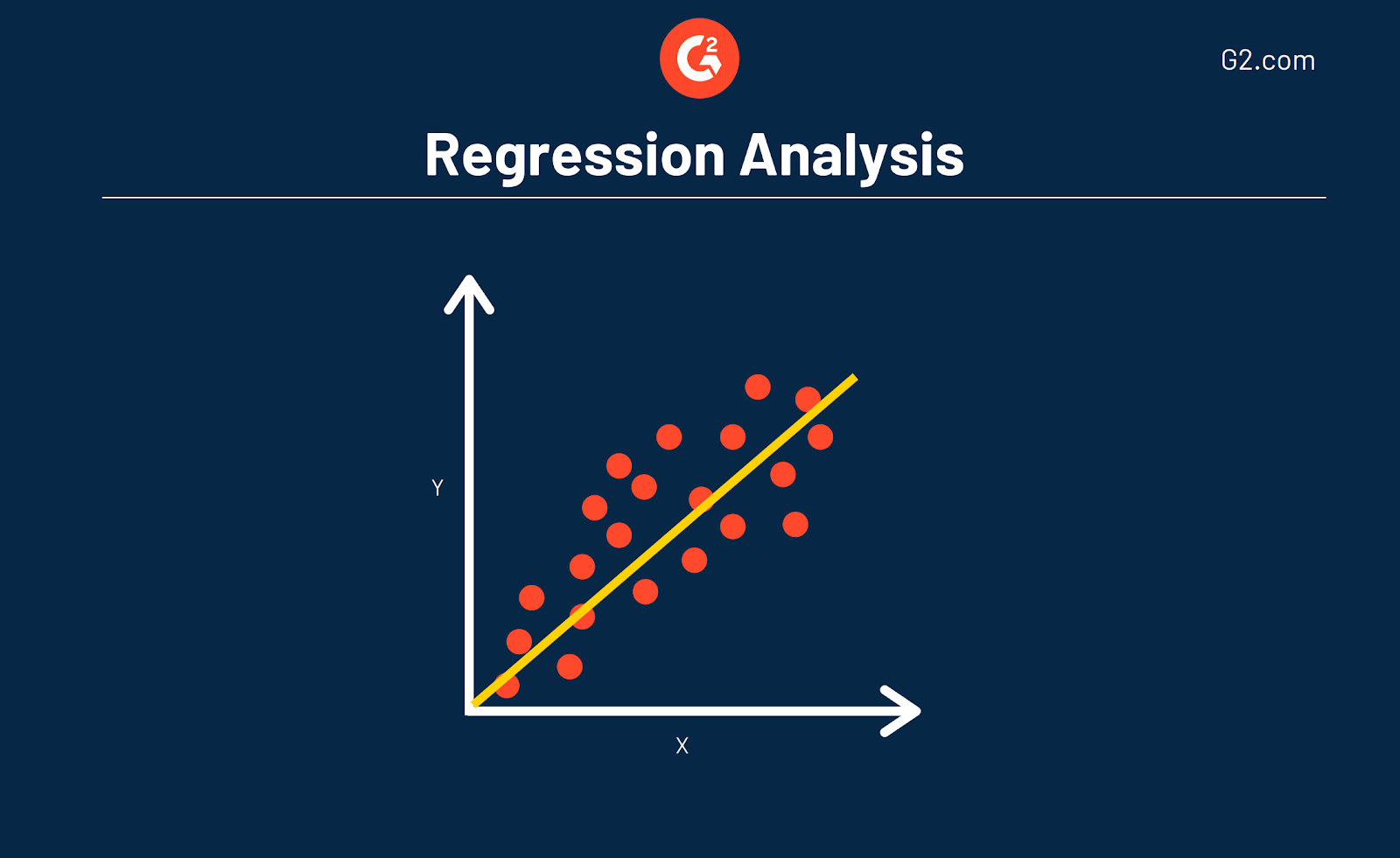
Ces études sont utilisées dans l’analyse statistique pour faire des prévisions et des tendances prévisionnelles. Par exemple, vous pouvez utiliser la régression pour prédire comment un produit ou un service spécifique peut se vendre à vos clients. Ou, ici à G2, nous utilisons la régression pour prédire à quoi ressemblera notre trafic organique dans 6 mois.
Formule de régression
La formule de régression utilisée pour voir à quoi pourraient ressembler les données à l’avenir est:
Y = a + b (x)
Dans cette formule:
- A fait référence à l’ordonnée à l’origine, la valeur de y lorsque x = 0
- X est la variable dépendante
- Y est la variable indépendante
- B fait référence à la pente, ou à la montée sur la course
L’inconvénient
Un inconvénient de l’utilisation la régression dans le cadre de votre analyse statistique est que la régression n’est pas très distinctive, ce qui signifie que bien que les valeurs aberrantes sur un nuage de points (ou un graphique d’analyse de régression) soient importantes, les raisons pour lesquelles elles sont aberrantes le sont également. Cette raison peut aller d’une erreur d’analyse à une mise à l’échelle inappropriée des données.
Un point de données marqué comme une valeur aberrante peut représenter de nombreuses choses, telles que votre produit le plus vendu. La ligne de régression vous incite à ignorer ces valeurs aberrantes et à ne voir que les tendances des données.
Test d’hypothèse
En analyse statistique, le test d’hypothèse, également appelé « Test T », est une clé pour tester les deux ensembles de variables aléatoires dans l’ensemble de données.
Cette méthode consiste à tester si un certain argument ou conclusion est vrai pour l’ensemble de données. Il permet de comparer les données avec diverses hypothèses et hypothèses. Il peut également aider à prévoir comment les décisions prises pourraient affecter l’entreprise.
En statistique, un test d’hypothèse détermine une certaine quantité sous une hypothèse donnée. Le résultat du test interprète si l’hypothèse est valable ou si l’hypothèse a été violée. Cette hypothèse est appelée hypothèse nulle, ou hypothèse 0. Toute autre hypothèse qui serait en violation de l’hypothèse 0 est appelée la première hypothèse, ou hypothèse 1.
Lorsque vous effectuez des tests d’hypothèses, les résultats du test sont significatifs pour les statistiques s’ils prouvent qu’il n’a pas pu se produire par hasard ou par hasard.
À titre d’exemple, vous pouvez supposer que plus il faut de temps pour développer un produit, plus il aura de succès, ce qui se traduira par des ventes plus élevées que jamais auparavant. Avant de mettre en œuvre des heures de travail plus longues pour développer un produit, les tests d’hypothèse s’assurent qu’il existe un lien réel entre les deux.
Formule de test d’hypothèse
Les résultats d’un test d’hypothèse statistique doivent être interprétés pour faire une revendication spécifique, appelée valeur p.
Disons que ce que vous cherchez à déterminer a 50% de chances d’être correct.
La formule de ce test d’hypothèse est:
H0: P = 0,5
H1:P ≠ 0.5
L’inconvénient
Les tests d’hypothèse peuvent parfois être assombris et biaisés par des erreurs courantes, comme l’effet placebo. Cela se produit lorsque les analystes statistiques qui effectuent le test s’attendent faussement à un certain résultat et voient ensuite ce résultat, quelles que soient les circonstances.
Il y a aussi la probabilité d’être faussé par l’effet Hawthorne, autrement connu sous le nom d’effet observateur. Cela se produit lorsque les participants analysés biaisent les résultats parce qu’ils savent qu’ils sont étudiés.
Connexes: En savoir plus sur les tests d’hypothèses précis avec une plongée en profondeur dans l’analyse inférentielle.
Détermination de la taille de l’échantillon
Lorsqu’il s’agit d’analyser des données à des fins d’analyse statistique, l’ensemble de données est parfois tout simplement trop volumineux, ce qui rend difficile la collecte de données précises pour chaque élément de l’ensemble de données. Lorsque c’est le cas, la plupart suivent la voie de l’analyse d’une taille d’échantillon, ou d’une taille plus petite, de données, appelée détermination de la taille de l’échantillon.
Pour ce faire correctement, vous devrez déterminer la bonne taille de l’échantillon pour être précis. Si la taille de l’échantillon est trop petite, vous n’aurez pas de résultats valides à la fin de votre analyse.
Pour arriver à cette conclusion, vous utiliserez l’une des nombreuses méthodes d’échantillonnage des données. Pour ce faire, vous pouvez envoyer une enquête à vos clients, puis utiliser la méthode d’échantillonnage aléatoire simple pour choisir les données client à analyser au hasard.
D’autre part, une taille d’échantillon trop importante peut entraîner une perte de temps et d’argent. Pour déterminer la taille de l’échantillon, vous pouvez examiner des aspects tels que le coût, le temps ou la commodité de la collecte des données.
Trouver une taille d’échantillon
Contrairement aux quatre autres méthodes d’analyse statistique, il n’existe pas une formule simple et rapide à utiliser pour trouver la taille de l’échantillon.
Cependant, il y a quelques conseils généraux à garder à l’esprit lors de la détermination de la taille d’un échantillon:
- Lorsque vous envisagez une taille d’échantillon plus petite, effectuez un recensement
- Utilisez une taille d’échantillon d’une étude similaire à la vôtre. Pour cela, vous pouvez envisager de consulter les bases de données académiques pour rechercher une étude similaire
- Si vous menez une étude générique, il peut y avoir un tableau qui existe déjà que vous pouvez utiliser à votre avantage
- Utilisez un calculateur de taille d’échantillon
- Ce n’est pas parce qu’il n’y a pas de formule spécifique que vous ne pourrez pas trouver une formule qui fonctionne. Il y en a beaucoup que vous pourriez utiliser, et cela dépend de ce que vous savez ou ne savez pas sur l’échantillon visé. Certains que vous pouvez envisager d’utiliser sont la formule de Slovin et la formule de Cochran
L’inconvénient
Lorsque vous analysez une variable de données nouvelle et non testée dans cette méthode, vous devrez vous fier à certaines hypothèses. Cela pourrait entraîner une hypothèse complètement inexacte. Si cette erreur se produit lors de cette méthode d’analyse statistique, elle peut affecter négativement le reste de votre analyse de données.
Ces erreurs sont appelées erreurs d’échantillonnage et sont mesurées par un intervalle de confiance. Par exemple, si vous déclarez que vos résultats sont à un niveau de confiance de 90%, cela signifie que si vous deviez effectuer la même analyse encore et encore, 90% du temps, vos résultats seront les mêmes.
Une méthode à la folie
Quelle que soit la méthode d’analyse statistique que vous choisissez, assurez-vous de prendre une note spéciale de chaque inconvénient potentiel, ainsi que de leur formule unique.
Bien sûr, il n’y a pas d’étalon-or ou de bonne ou de mauvaise méthode à utiliser. Cela dépendra du type de données que vous avez collectées, ainsi que des informations que vous cherchez à avoir comme résultat final.
Vous souhaitez trouver le bon outil pour approfondir votre analyse des données ? Découvrez notre tour d’horizon des meilleurs logiciels d’analyse statistique pour les analyses les plus complexes.