L’analyse statistique consiste à étudier les tendances, les modèles et les relations à l’aide de données quantitatives. C’est un outil de recherche important utilisé par les scientifiques, les gouvernements, les entreprises et d’autres organisations.
Pour tirer des conclusions valables, l’analyse statistique nécessite une planification minutieuse dès le début du processus de recherche. Vous devez spécifier vos hypothèses et prendre des décisions concernant votre plan de recherche, la taille de l’échantillon et la procédure d’échantillonnage.
Après avoir collecté les données de votre échantillon, vous pouvez organiser et résumer les données à l’aide de statistiques descriptives. Ensuite, vous pouvez utiliser des statistiques inférentielles pour tester formellement des hypothèses et faire des estimations sur la population. Enfin, vous pouvez interpréter et généraliser vos résultats.
Cet article est une introduction pratique à l’analyse statistique pour les étudiants et les chercheurs. Nous vous guiderons à travers les étapes en utilisant deux exemples de recherche. Le premier étudie une relation de cause à effet potentielle, tandis que le second étudie une corrélation potentielle entre les variables.
Étape 1: Rédigez vos hypothèses et planifiez votre plan de recherche
Pour collecter des données valides à des fins d’analyse statistique, vous devez d’abord spécifier vos hypothèses et planifier votre plan de recherche.
Rédaction d’hypothèses statistiques
Le but de la recherche est souvent d’étudier une relation entre les variables au sein d’une population. Vous commencez par une prédiction et utilisez une analyse statistique pour tester cette prédiction.
Une hypothèse statistique est un moyen formel d’écrire une prédiction sur une population. Chaque prédiction de recherche est reformulée en hypothèses nulles et alternatives qui peuvent être testées à l’aide de données d’échantillon.
Alors que l’hypothèse nulle ne prédit toujours aucun effet ou aucune relation entre les variables, l’hypothèse alternative indique votre prédiction de recherche d’un effet ou d’une relation.
- Hypothèse nulle: Un exercice de méditation de 5 minutes n’aura aucun effet sur les résultats des tests de mathématiques chez les adolescents.
- Hypothèse alternative: Un exercice de méditation de 5 minutes améliorera les résultats des tests de mathématiques chez les adolescents.
- Hypothèse nulle: Le revenu parental et la GPA n’ont aucune relation entre eux chez les étudiants.
- Hypothèse alternative: Le revenu parental et la GPA sont positivement corrélés chez les étudiants.
Planification de votre conception de recherche
Une conception de recherche est votre stratégie globale de collecte et d’analyse de données. Il détermine les tests statistiques que vous pouvez utiliser pour tester votre hypothèse plus tard.
Tout d’abord, décidez si votre recherche utilisera un plan descriptif, corrélatif ou expérimental. Les expériences influencent directement les variables, alors que les études descriptives et corrélatives ne mesurent que les variables.
- Dans un plan expérimental, vous pouvez évaluer une relation de cause à effet (par exemple, l’effet de la méditation sur les résultats des tests) à l’aide de tests statistiques de comparaison ou de régression.
- Dans un plan de corrélation, vous pouvez explorer les relations entre les variables (par ex., revenu parental et GPA) sans aucune hypothèse de causalité à l’aide de coefficients de corrélation et de tests de signification.
- Dans un plan descriptif, vous pouvez étudier les caractéristiques d’une population ou d’un phénomène (par exemple, la prévalence de l’anxiété chez les étudiants américains) à l’aide de tests statistiques pour tirer des conclusions à partir de données d’échantillon.
Votre conception de recherche concerne également la comparaison des participants au niveau du groupe ou au niveau individuel, ou les deux.
- Dans une conception entre sujets, vous comparez les résultats au niveau du groupe des participants qui ont été exposés à différents traitements (par exemple, ceux qui ont effectué un exercice de méditation par rapport à ceux qui ne l’ont pas fait).
- Dans une conception intra-sujets, vous comparez les mesures répétées des participants qui ont participé à tous les traitements d’une étude (par exemple, les scores avant et après avoir effectué un exercice de méditation).
- Expérimental
- Corrélationnel
Tout d’abord, vous prendrez les résultats des tests de base des participants. Ensuite, vos participants subiront un exercice de méditation de 5 minutes. Enfin, vous enregistrerez les scores des participants à un deuxième test de mathématiques.
Dans cette expérience, la variable indépendante est l’exercice de méditation de 5 minutes, et la variable dépendante est le changement des résultats des tests de mathématiques avant et après l’intervention.
Il n’y a pas de variables dépendantes ou indépendantes dans cette étude, car vous voulez seulement mesurer des variables sans les influencer d’aucune façon.
Mesure des variables
Lors de la planification d’un plan de recherche, vous devez opérationnaliser vos variables et décider exactement comment vous les mesurerez.
Pour l’analyse statistique, il est important de considérer le niveau de mesure de vos variables, qui vous indique le type de données qu’elles contiennent:
- Les données catégorielles représentent des regroupements. Ceux-ci peuvent être nominaux (par ex., genre) ou ordinaux (par exemple, niveau de capacité linguistique).
- Les données quantitatives représentent les quantités. Ceux-ci peuvent être sur une échelle d’intervalle (par exemple, score au test) ou une échelle de ratio (par exemple, âge).
De nombreuses variables peuvent être mesurées à différents niveaux de précision. Par exemple, les données d’âge peuvent être quantitatives (8 ans) ou catégoriques (jeunes). Si une variable est codée numériquement (par exemple, niveau d’accord de 1 à 5), cela ne signifie pas automatiquement qu’elle est quantitative au lieu de catégorique.
Il est important d’identifier le niveau de mesure pour choisir des statistiques et des tests d’hypothèse appropriés. Par exemple, vous pouvez calculer un score moyen avec des données quantitatives, mais pas avec des données catégorielles.
Dans une étude de recherche, avec des mesures de vos variables d’intérêt, vous collecterez souvent des données sur les caractéristiques pertinentes des participants.
- Expérimental
- Corrélationnel
| Variable | Type de données |
|---|---|
| Âge | Quantitatif (ratio) |
| Sexe | Catégorique (nominal) |
| Race ou origine ethnique | Catégorique (nominal) |
| Résultats des tests de base | Quantitatifs (intervalle) |
| Résultats des tests finaux | Quantitatifs (intervalle) |
| Variable | Type de données |
|---|---|
| Revenu parental | Quantitatif (ratio) |
| GPA | Quantitative (intervalle) |
Étape 2: Recueillir des données à partir d’un échantillon
Dans la plupart des cas, il est trop difficile ou trop coûteux de collecter des données auprès de chaque membre de la population que vous souhaitez étudier. Au lieu de cela, vous collecterez des données à partir d’un échantillon.
L’analyse statistique vous permet d’appliquer vos résultats au-delà de votre propre échantillon à condition d’utiliser des procédures d’échantillonnage appropriées. Vous devez viser un échantillon représentatif de la population.
Échantillonnage pour analyse statistique
Il existe deux approches principales pour sélectionner un échantillon.
- Échantillonnage probabiliste: chaque membre de la population a une chance d’être sélectionné pour l’étude par sélection aléatoire.
- Échantillonnage non probabiliste: certains membres de la population sont plus susceptibles que d’autres d’être sélectionnés pour l’étude en raison de critères tels que la commodité ou l’auto-sélection volontaire.
En théorie, pour des résultats hautement généralisables, vous devez utiliser une méthode d’échantillonnage probabiliste. La sélection aléatoire réduit le biais d’échantillonnage et garantit que les données de votre échantillon sont réellement typiques de la population. Des tests paramétriques peuvent être utilisés pour faire des inférences statistiques solides lorsque les données sont collectées à l’aide d’un échantillonnage probabiliste.
Mais en pratique, il est rarement possible de recueillir l’échantillon idéal. Bien que les échantillons non probabilistes soient plus susceptibles d’être biaisés, ils sont beaucoup plus faciles à recruter et à collecter des données. Les tests non paramétriques sont plus appropriés pour les échantillons non probabilistes, mais ils entraînent des inférences plus faibles sur la population.
Si vous souhaitez utiliser des tests paramétriques pour des échantillons non probabilistes, vous devez faire valoir que:
- votre échantillon est représentatif de la population à laquelle vous généralisez vos résultats.
- votre échantillon n’a pas de biais systématique.
Gardez à l’esprit que la validité externe signifie que vous ne pouvez généraliser vos conclusions qu’à d’autres personnes partageant les caractéristiques de votre échantillon. Par exemple, les résultats d’échantillons occidentaux, instruits, Industrialisés, Riches et Démocratiques (p. ex., étudiants aux États-Unis) ne sont pas automatiquement applicables à toutes les populations non ÉTRANGES.
Si vous appliquez des tests paramétriques aux données d’échantillons non probabilistes, assurez-vous de préciser les limites de la généralisation de vos résultats dans votre section de discussion.
Créez une procédure d’échantillonnage appropriée
En fonction des ressources disponibles pour votre recherche, décidez de la façon dont vous recruterez les participants.
- Aurez-vous des ressources pour faire connaître largement votre étude, y compris en dehors de votre milieu universitaire?
- Aurez-vous les moyens de recruter un échantillon diversifié qui représente une vaste population?
- Avez-vous le temps de contacter et de faire le suivi avec les membres de groupes difficiles à joindre?
- Expérimental
- Corrélationnel
Vos participants sont auto-sélectionnés par leurs écoles. Bien que vous utilisiez un échantillon non probabiliste, vous visez un échantillon diversifié et représentatif.
Vos participants se portent volontaires pour l’enquête, ce qui en fait un échantillon non probabiliste.
Calculez une taille d’échantillon suffisante
Avant de recruter des participants, décidez de la taille de votre échantillon soit en examinant d’autres études dans votre domaine, soit en utilisant des statistiques. Un échantillon trop petit peut ne pas être représentatif de l’échantillon, tandis qu’un échantillon trop grand sera plus coûteux que nécessaire.
Il existe de nombreuses calculatrices de taille d’échantillon en ligne. Différentes formules sont utilisées selon que vous avez des sous-groupes ou la rigueur de votre étude (par exemple, en recherche clinique). En règle générale, un minimum de 30 unités ou plus par sous-groupe est nécessaire.
Pour utiliser ces calculatrices, vous devez comprendre et saisir ces composants clés:
- Niveau de signification (alpha): le risque de rejeter une véritable hypothèse nulle que vous êtes prêt à prendre, généralement fixé à 5%.
- Puissance statistique: la probabilité que votre étude détecte un effet d’une certaine taille s’il y en a un, généralement de 80% ou plus.
- Taille de l’effet attendu: une indication standardisée de l’ampleur du résultat attendu de votre étude, généralement basée sur d’autres études similaires.
- Écart-type de la population : estimation du paramètre de la population basée sur une étude antérieure ou une étude pilote.

Étape 3: Résumez vos données avec des statistiques descriptives
Une fois que vous avez collecté toutes vos données, vous pouvez les inspecter et calculer des statistiques descriptives qui les résument.
Inspectez vos données
Il existe différentes façons d’inspecter vos données, notamment les suivantes:
- Organiser les données de chaque variable dans des tableaux de distribution de fréquences.
- Affichage des données d’une variable clé dans un graphique à barres pour afficher la distribution des réponses.
- Visualisation de la relation entre deux variables à l’aide d’un nuage de points.
En visualisant vos données sous forme de tableaux et de graphiques, vous pouvez évaluer si vos données suivent une distribution biaisée ou normale et s’il existe des valeurs aberrantes ou des données manquantes.
Une distribution normale signifie que vos données sont réparties symétriquement autour d’un centre où se trouvent la plupart des valeurs, les valeurs s’effilochant aux extrémités de la queue.
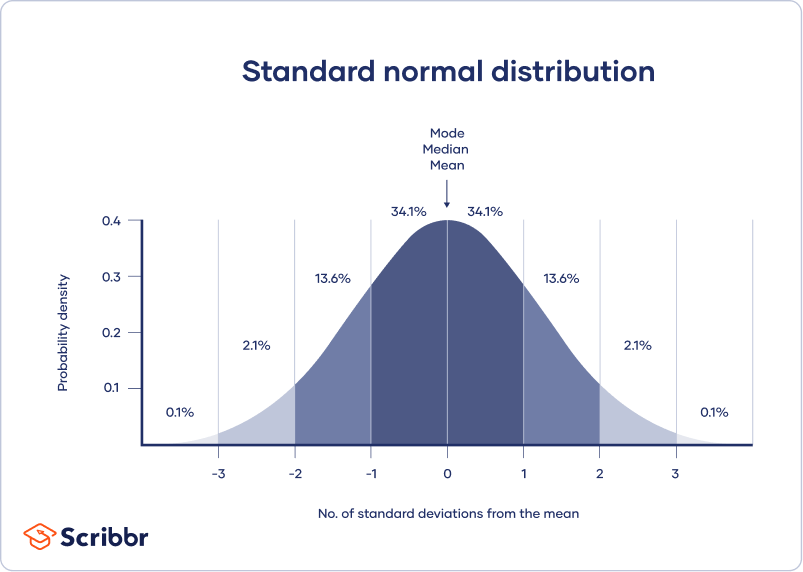
En revanche, une distribution asymétrique est asymétrique et a plus de valeurs à une extrémité que l’autre. Il est important de garder à l’esprit la forme de la distribution, car seules certaines statistiques descriptives doivent être utilisées avec des distributions asymétriques.
Les valeurs aberrantes extrêmes peuvent également produire des statistiques trompeuses, vous devrez donc peut-être adopter une approche systématique pour traiter ces valeurs.
Calculer les mesures de tendance centrale
Les mesures de tendance centrale décrivent où se trouvent la plupart des valeurs d’un ensemble de données. Trois mesures principales de la tendance centrale sont souvent rapportées:
- Mode : la réponse ou la valeur la plus populaire dans l’ensemble de données.
- Médiane: la valeur au milieu exact de l’ensemble de données lorsqu’elle est ordonnée de faible à élevé.
- Moyenne : la somme de toutes les valeurs divisée par le nombre de valeurs.
Cependant, selon la forme de la distribution et le niveau de mesure, seule une ou deux de ces mesures peuvent être appropriées. Par exemple, de nombreuses caractéristiques démographiques ne peuvent être décrites qu’en utilisant le mode ou les proportions, alors qu’une variable comme le temps de réaction peut ne pas avoir de mode du tout.
Calculer les mesures de variabilité
Les mesures de variabilité vous indiquent la répartition des valeurs dans un ensemble de données. Quatre mesures principales de la variabilité sont souvent rapportées:
- Plage : la valeur la plus élevée moins la valeur la plus basse de l’ensemble de données.
- Plage interquartile : plage de la moitié moyenne de l’ensemble de données.
- Écart type : distance moyenne entre chaque valeur de votre ensemble de données et la moyenne.
- Variance : le carré de l’écart type.
Encore une fois, la forme de la distribution et le niveau de mesure devraient guider votre choix de statistiques de variabilité. La plage interquartile est la meilleure mesure pour les distributions asymétriques, tandis que l’écart type et la variance fournissent les meilleures informations pour les distributions normales.
- Expérimental
- Corrélationnel
À l’aide de votre table, vous devez vérifier si les unités des statistiques descriptives sont comparables pour les scores pré-test et post-test. Par exemple, les niveaux de variance sont-ils similaires entre les groupes? Y a-t-il des valeurs extrêmes? Le cas échéant, vous devrez peut-être identifier et supprimer des valeurs aberrantes extrêmes dans votre ensemble de données ou transformer vos données avant d’effectuer un test statistique.
| Scores avant le test | Scores après le test | |
|---|---|---|
| Moyenne | 68.44 | 75.25 |
| Écart type | 9.43 | 9.88 |
| Écart | 88.96 | 97.96 |
| Gamme | 36.25 | 45.12 |
| L | 30 | |
À partir de ce tableau, nous pouvons voir que le score moyen a augmenté après l’exercice de méditation et que les variances des deux scores sont comparables. Ensuite, nous pouvons effectuer un test statistique pour savoir si cette amélioration des scores aux tests est statistiquement significative dans la population.
Il est important de vérifier si vous disposez d’un large éventail de points de données. Si vous ne le faites pas, vos données peuvent être biaisées vers certains groupes plus que d’autres (par exemple, les résultats scolaires élevés), et seules des inférences limitées peuvent être faites sur une relation.
| Revenu parental (USD) | GPA | |
|---|---|---|
| Moyenne | 62,100 | 3.12 |
| Écart type | 15,000 | 0.45 |
| Écart | 225,000,000 | 0.16 |
| Gamme | 8,000–378,000 | 2.64–4.00 |
| L | 653 | |
Ensuite, nous pouvons calculer un coefficient de corrélation et effectuer un test statistique pour comprendre la signification de la relation entre les variables dans la population.
Étape 4: Tester des hypothèses ou faire des estimations avec des statistiques inférentielles
Un nombre qui décrit un échantillon est appelé une statistique, tandis qu’un nombre décrivant une population est appelé un paramètre. À l’aide de statistiques inférentielles, vous pouvez tirer des conclusions sur les paramètres de population en fonction de statistiques d’échantillons.
Les chercheurs utilisent souvent deux méthodes principales (simultanément) pour faire des inférences dans les statistiques.
- Estimation : calcul des paramètres de population sur la base de statistiques d’échantillons.
- Test d’hypothèse: un processus formel pour tester les prédictions de recherche sur la population à l’aide d’échantillons.
Estimation
Vous pouvez effectuer deux types d’estimations de paramètres de population à partir de statistiques d’échantillons:
- Une estimation ponctuelle: une valeur qui représente votre meilleure estimation du paramètre exact.
- Une estimation d’intervalle: une plage de valeurs qui représentent votre meilleure estimation de l’emplacement du paramètre.
Si votre objectif est d’inférer et de rapporter des caractéristiques de population à partir de données d’échantillons, il est préférable d’utiliser des estimations ponctuelles et d’intervalles dans votre article.
Vous pouvez considérer une statistique d’échantillon comme une estimation ponctuelle du paramètre de population lorsque vous avez un échantillon représentatif (par exemple, dans un vaste sondage d’opinion publique, la proportion d’un échantillon qui soutient le gouvernement actuel est prise comme la proportion de la population des partisans du gouvernement).
Il y a toujours une erreur dans l’estimation, vous devez donc également fournir un intervalle de confiance en tant qu’estimation d’intervalle pour montrer la variabilité autour d’une estimation ponctuelle.
Un intervalle de confiance utilise l’erreur type et le score z de la distribution normale standard pour indiquer où vous vous attendez généralement à trouver le paramètre de population la plupart du temps.
Test d’hypothèses
À l’aide des données d’un échantillon, vous pouvez tester des hypothèses sur les relations entre les variables de la population. Le test d’hypothèse commence par l’hypothèse que l’hypothèse nulle est vraie dans la population, et vous utilisez des tests statistiques pour évaluer si l’hypothèse nulle peut être rejetée ou non.
Les tests statistiques déterminent où se situeraient vos données d’échantillon sur une distribution attendue des données d’échantillon si l’hypothèse nulle était vraie. Ces tests donnent deux sorties principales:
- Une statistique de test vous indique dans quelle mesure vos données diffèrent de l’hypothèse nulle du test.
- Une valeur p vous indique la probabilité d’obtenir vos résultats si l’hypothèse nulle est réellement vraie dans la population.
Les tests statistiques se déclinent en trois variétés principales:
- Les tests de comparaison évaluent les différences de résultats entre les groupes.
- Les tests de régression évaluent les relations de cause à effet entre les variables.
- Les tests de corrélation évaluent les relations entre les variables sans supposer de causalité.
Votre choix de test statistique dépend de vos questions de recherche, du plan de recherche, de la méthode d’échantillonnage et des caractéristiques des données.
Tests paramétriques
Les tests paramétriques font des inférences puissantes sur la population à partir de données d’échantillons. Mais pour les utiliser, certaines hypothèses doivent être remplies et seuls certains types de variables peuvent être utilisés. Si vos données violent ces hypothèses, vous pouvez effectuer des transformations de données appropriées ou utiliser d’autres tests non paramétriques à la place.
Une régression modélise la mesure dans laquelle les changements dans une variable prédictive entraînent des changements dans la ou les variables de résultat.
- Une régression linéaire simple comprend une variable prédictive et une variable de résultat.
- Une régression linéaire multiple comprend deux variables prédictives ou plus et une variable de résultat.
Les tests de comparaison comparent généralement les moyennes des groupes. Il peut s’agir des moyennes de différents groupes au sein d’un échantillon (par exemple, un groupe de traitement et un groupe témoin), des moyennes d’un groupe d’échantillon prélevées à des moments différents (par exemple, les scores avant et après le test), ou d’une moyenne d’échantillon et d’une moyenne de population.
- Un test t concerne exactement 1 ou 2 groupes lorsque l’échantillon est petit (30 ou moins).
- Un test z concerne exactement 1 ou 2 groupes lorsque l’échantillon est volumineux.
- Une ANOVA est pour 3 groupes ou plus.
Les tests z et t ont des sous-types basés sur le nombre et les types d’échantillons et les hypothèses:
- Si vous n’avez qu’un seul échantillon que vous souhaitez comparer à une moyenne de population, utilisez un test à un échantillon.
- Si vous avez des mesures appariées (conception intra-sujets), utilisez un test d’échantillons dépendants (appariés).
- Si vous avez des mesures complètement distinctes de deux groupes inégalés (conception entre sujets), utilisez un test d’échantillons indépendant.
- Si vous vous attendez à une différence entre les groupes dans une direction spécifique, utilisez un test à une queue.
- Si vous n’avez pas d’attentes quant à la direction d’une différence entre les groupes, utilisez un test à deux queues.
Le seul test de corrélation paramétrique est le r de Pearson. Le coefficient de corrélation (r) vous indique la force d’une relation linéaire entre deux variables quantitatives.
Cependant, pour vérifier si la corrélation dans l’échantillon est suffisamment forte pour être importante dans la population, vous devez également effectuer un test de signification du coefficient de corrélation, généralement un test t, pour obtenir une valeur p. Ce test utilise la taille de votre échantillon pour calculer dans quelle mesure le coefficient de corrélation diffère de zéro dans la population.
- Expérimental
- Corrélationnel
Vous utilisez un test de t à une queue à échantillons dépendants pour évaluer si l’exercice de méditation a considérablement amélioré les résultats des tests de mathématiques. Le test vous donne:
- une valeur t (statistique de test) de 3,00
- une valeur p de 0.0028
Bien que le r de Pearson soit une statistique de test, il ne vous dit rien sur l’importance de la corrélation dans la population. Vous devez également vérifier si ce coefficient de corrélation de l’échantillon est suffisamment important pour démontrer une corrélation dans la population.
Un test t peut également déterminer dans quelle mesure un coefficient de corrélation diffère de zéro en fonction de la taille de l’échantillon. Puisque vous vous attendez à une corrélation positive entre le revenu parental et la GPA, vous utilisez un test t à un échantillon et à une queue. Le test t vous donne:
- une valeur t de 3,08
- une valeur p de 0.001
Étape 5: Interpréter vos résultats
La dernière étape de l’analyse statistique consiste à interpréter vos résultats.
Signification statistique
Dans les tests d’hypothèse, la signification statistique est le principal critère pour tirer des conclusions. Vous comparez votre valeur p à un niveau de signification défini (généralement 0,05) pour décider si vos résultats sont statistiquement significatifs ou non significatifs.
Il est peu probable que des résultats statistiquement significatifs soient apparus uniquement par hasard. Il n’y a que très peu de chances qu’un tel résultat se produise si l’hypothèse nulle est vraie dans la population.
- Expérimental
- Corrélationnel
Cela signifie que vous croyez que l’intervention de méditation, plutôt que des facteurs aléatoires, a directement causé l’augmentation des scores aux tests.
Notez que corrélation ne signifie pas toujours causalité, car il existe souvent de nombreux facteurs sous-jacents contribuant à une variable complexe comme la GPA. Même si une variable est liée à une autre, cela peut être dû à une troisième variable influençant les deux, ou à des liens indirects entre les deux variables.
Une grande taille d’échantillon peut également influencer fortement la signification statistique d’un coefficient de corrélation en faisant en sorte que de très petits coefficients de corrélation semblent significatifs.
Taille de l’effet
Un résultat statistiquement significatif ne signifie pas nécessairement qu’il existe des applications réelles ou des résultats cliniques importants pour une découverte.
En revanche, la taille de l’effet indique la signification pratique de vos résultats. Il est important de signaler la taille des effets ainsi que vos statistiques inférentielles pour obtenir une image complète de vos résultats. Vous devez également signaler des estimations d’intervalle de la taille des effets si vous rédigez un article de style APA.
- Expérimental
- Corrélationnel
Avec un d de Cohen de 0.72, il y a une signification pratique moyenne à élevée à votre constat que l’exercice de méditation a amélioré les résultats des tests.
Étant donné que votre valeur se situe entre 0,1 et 0,3, votre conclusion d’une relation entre le revenu parental et la GPA représente un effet très faible et a une signification pratique limitée.
Les erreurs de décision
Les erreurs de type I et de type II sont des erreurs commises dans les conclusions de la recherche. Une erreur de type I signifie rejeter l’hypothèse nulle lorsqu’elle est réellement vraie, tandis qu’une erreur de type II signifie ne pas rejeter l’hypothèse nulle lorsqu’elle est fausse.
Vous pouvez viser à minimiser le risque de ces erreurs en sélectionnant un niveau de signification optimal et en garantissant une puissance élevée. Cependant, il y a un compromis entre les deux erreurs, donc un équilibre fin est nécessaire.
Statistiques fréquentistes par rapport aux statistiques bayésiennes
Traditionnellement, les statistiques fréquentistes mettent l’accent sur le test de signification des hypothèses nulles et commencent toujours par l’hypothèse d’une véritable hypothèse nulle.
Cependant, la statistique bayésienne a gagné en popularité en tant qu’approche alternative au cours des dernières décennies. Dans cette approche, vous utilisez des recherches antérieures pour mettre à jour continuellement vos hypothèses en fonction de vos attentes et de vos observations.
Le facteur de Bayes compare la force relative des preuves pour l’hypothèse nulle par rapport à l’hypothèse alternative plutôt que de tirer une conclusion sur le rejet ou non de l’hypothèse nulle.
Foire aux questions sur l’analyse statistique
L’analyse statistique est la principale méthode d’analyse des données de recherche quantitative. Il utilise des probabilités et des modèles pour tester les prédictions sur une population à partir de données d’échantillons.
Les statistiques descriptives résument les caractéristiques d’un ensemble de données. Les statistiques inférentielles vous permettent de tester une hypothèse ou d’évaluer si vos données sont généralisables à l’ensemble de la population.
Le test d’hypothèse est une procédure formelle pour étudier nos idées sur le monde à l’aide de statistiques. Il est utilisé par les scientifiques pour tester des prédictions spécifiques, appelées hypothèses, en calculant la probabilité qu’un modèle ou une relation entre les variables ait pu apparaître par hasard.
Dans les tests d’hypothèses statistiques, l’hypothèse nulle d’un test ne prédit toujours aucun effet ou aucune relation entre les variables, tandis que l’hypothèse alternative indique votre prédiction de recherche d’un effet ou d’une relation.
Signification statistique est un terme utilisé par les chercheurs pour affirmer qu’il est peu probable que leurs observations aient pu se produire sous l’hypothèse nulle d’un test statistique. La signification est généralement désignée par une valeur p ou une valeur de probabilité.
La signification statistique est arbitraire – elle dépend du seuil, ou valeur alpha, choisi par le chercheur. Le seuil le plus courant est p < 0,05, ce qui signifie que les données sont susceptibles de se produire moins de 5% du temps dans l’hypothèse nulle.
Lorsque la valeur p tombe en dessous de la valeur alpha choisie, nous disons que le résultat du test est statistiquement significatif.