Statistisk analyse betyr å undersøke trender, mønstre og relasjoner ved hjelp av kvantitative data. Det er et viktig forskningsverktøy som brukes av forskere, myndigheter, bedrifter og andre organisasjoner.
for å trekke gyldige konklusjoner krever statistisk analyse nøye planlegging fra starten av forskningsprosessen. Du må spesifisere hypotesene dine og ta beslutninger om forskningsdesign, prøvestørrelse og prøvetakingsprosedyre.
etter at du har samlet inn data fra prøven, kan du organisere og oppsummere dataene ved hjelp av beskrivende statistikk. Deretter kan du bruke inferensiell statistikk til å formelt teste hypoteser og gjøre estimater om befolkningen. Til slutt kan du tolke og generalisere funnene dine.
denne artikkelen er en praktisk innføring i statistisk analyse for studenter og forskere. Vi vil lede deg gjennom trinnene ved hjelp av to forskningseksempler. Den første undersøker et potensielt årsakssammenheng, mens den andre undersøker en potensiell korrelasjon mellom variabler.
Trinn 1: Skriv hypotesene dine og planlegg forskningsdesignet
for å samle gyldige data for statistisk analyse må du først spesifisere hypotesene dine og planlegge forskningsdesignet ditt.
Skrive statistiske hypoteser
målet med forskning er ofte å undersøke et forhold mellom variabler i en populasjon. Du starter med en prediksjon, og bruker statistisk analyse for å teste den prediksjonen.
en statistisk hypotese er en formell måte å skrive en prediksjon om en befolkning. Hver forskning prediksjon omformuleres til null og alternative hypoteser som kan testes ved hjelp av eksempeldata.
mens nullhypotesen alltid forutsier ingen effekt eller ingen sammenheng mellom variabler, angir den alternative hypotesen din forskningspåvisning av en effekt eller forhold.
- Nullhypotese: en 5-minutters meditasjonsøvelse vil ikke ha noen effekt på matte testresultater hos tenåringer.
- Alternativ hypotese: en 5-minutters meditasjonsøvelse vil forbedre matte testresultater hos tenåringer.
- Null hypotese: Foreldrenes inntekt og GPA har ingen sammenheng med hverandre i studenter.
- Alternativ hypotese: Foreldrenes inntekt og GPA er positivt korrelert i studenter.
Planlegging av forskningsdesign
et forskningsdesign er din overordnede strategi for datainnsamling og analyse. Det bestemmer de statistiske testene du kan bruke til å teste hypotesen din senere.
først avgjøre om forskningen din vil bruke en beskrivende, korrelasjonell eller eksperimentell design. Eksperimenter påvirker variabler direkte, mens beskrivende og korrelasjonsstudier bare måler variabler.
- i et eksperimentelt design kan du vurdere et årsak-og-effekt-forhold (f. eks. effekten av meditasjon på testresultater) ved hjelp av statistiske tester av sammenligning eller regresjon.
- i en korrelasjonsdesign kan du utforske sammenhenger mellom variabler (f. eks. gpa) uten noen antagelse om årsakssammenheng ved hjelp av korrelasjonskoeffisienter og signifikans tester.
- i en beskrivende design kan du studere egenskapene til en befolkning eller et fenomen (f.eks. forekomsten av angst hos amerikanske studenter) ved hjelp av statistiske tester for å trekke avledninger fra prøvedata.
forskningsdesignet ditt gjelder også om du vil sammenligne deltakere på gruppenivå eller individuelt nivå, eller begge deler.
- i et mellomfagsdesign sammenligner du resultatene på gruppenivå fra deltakere som har vært utsatt for ulike behandlinger (f.eks. de som utførte en meditasjonsøvelse mot de som ikke gjorde det).
- i en innen-fagdesign sammenligner du gjentatte tiltak fra deltakere som har deltatt i alle behandlinger av en studie(f. eks. score fra før og etter å ha utført en meditasjonsøvelse).
- Eksperimentell
- Korrelasjonell
først tar du utgangspunkt i testresultater fra deltakere. Deretter vil deltakerne gjennomgå en 5-minutters meditasjonsøvelse. Til slutt vil du registrere deltakernes score fra en annen matteprøve.
i dette eksperimentet er den uavhengige variabelen 5-minutters meditasjonsøvelse, og den avhengige variabelen er endringen i matteprøven fra før og etter intervensjonen.
det er ingen avhengige eller uavhengige variabler i denne studien, fordi du bare vil måle variabler uten å påvirke dem på noen måte.
Måle variabler
når du planlegger et forskningsdesign, bør du operasjonalisere variablene dine og bestemme nøyaktig hvordan du skal måle dem.
for statistisk analyse er det viktig å vurdere målingsnivået for variablene dine, som forteller deg hva slags data de inneholder:
- Kategoriske data representerer grupperinger. Disse kan være nominelle (f. eks. kjønn) eller ordinal (f. eks. nivå av språkferdighet).
- Kvantitative data representerer mengder. Disse kan være på en intervallskala (f.eks. testscore) eller en forholdsskala (f. eks. alder).
Mange variabler kan måles på forskjellige nivåer av presisjon. For eksempel kan aldersdata være kvantitative (8 år) eller kategoriske (unge). Nivå av avtale fra 1-5), betyr det ikke automatisk at det er kvantitativt i stedet for kategorisk.
Identifisering av målenivå er viktig for å velge passende statistikk og hypotesetester. For eksempel kan du beregne en gjennomsnittlig poengsum med kvantitative data, men ikke med kategoriske data.
i en forskningsstudie, sammen med målinger av dine variabler av interesse, vil du ofte samle inn data om relevante deltakeregenskaper.
- Eksperimentell
- Korrelasjonell
| Variabel | Datatype |
|---|---|
| Alder | Kvantitativ (forhold) |
| Kjønn | Kategorisk (nominell) |
| Rase eller etnisitet | Kategorisk (nominell) |
| Baseline testresultater | Kvantitativ (intervall) |
| Endelige testresultater | Kvantitativ (intervall) |
| Variabel | Datatype |
|---|---|
| Foreldrenes inntekt | Kvantitativ (forhold) |
| Gpa | Kvantitativ (intervall) |
Trinn 2: Samle inn data fra et utvalg
I de fleste tilfeller er det for vanskelig eller dyrt å samle inn data fra hvert medlem av befolkningen du er interessert i å studere. I stedet samler du inn data fra et utvalg.
Statistisk analyse lar deg bruke dine funn utover din egen prøve så lenge du bruker passende prøvetakingsprosedyrer. Du bør sikte på et utvalg som er representativt for befolkningen.
Prøvetaking for statistisk analyse
det er to hovedmetoder for å velge et utvalg.
- Sannsynlighetsprøve: hvert medlem av befolkningen har en sjanse til å bli valgt for studien gjennom tilfeldig utvalg.
- ikke-sannsynlighetsprøve: noen medlemmer av befolkningen er mer sannsynlige enn andre for å bli valgt for studien på grunn av kriterier som bekvemmelighet eller frivillig selvvalg.
i teorien, for svært generaliserbare funn, bør du bruke en sannsynlighetsprøvemetode. Tilfeldig utvalg reduserer utvalgsskjevhet og sikrer at data fra utvalget ditt faktisk er typisk for populasjonen. Parametriske tester kan brukes til å lage sterke statistiske slutninger når data samles inn ved hjelp av sannsynlighetsprøve.
Men i praksis er det sjelden mulig å samle den ideelle prøven. Mens ikke-sannsynlighetsprøver er mer sannsynlig å være partisk, er de mye lettere å rekruttere og samle inn data fra. Ikke-parametriske tester er mer passende for ikke-sannsynlighetsprøver, men de resulterer i svakere slutninger om befolkningen.
hvis du vil bruke parametriske tester for ikke-sannsynlighetsprøver, må du gjøre saken som:
- prøven din er representativ for befolkningen du generaliserer funnene dine til.
- prøven mangler systematisk skjevhet.
husk at ekstern validitet betyr at du bare kan generalisere konklusjonene dine til andre som deler egenskapene til prøven din. For eksempel resultater fra Vestlige, Utdannede, Industrialiserte, Rike og Demokratiske prøver (f. eks., studenter i USA) gjelder ikke automatisk for alle IKKE-RARE populasjoner.
hvis du bruker parametriske tester på data fra ikke-sannsynlighetsprøver, må du utdype begrensningene for hvor langt resultatene dine kan generaliseres i diskusjonsseksjonen.
Opprett en passende prøvetakingsprosedyre
basert på ressursene som er tilgjengelige for forskningen din, bestemmer du hvordan du skal rekruttere deltakere.
- Vil du ha ressurser til å annonsere studiet ditt mye, inkludert utenfor universitetsinnstillingen din?
- Vil du ha midler til å rekruttere et mangfoldig utvalg som representerer en bred befolkning?
- har du tid til å kontakte og følge opp medlemmer av vanskelig tilgjengelige grupper?
- Eksperimentell
- Korrelasjonell
dine deltakere er selvvalgt av sine skoler. Selv om du bruker en ikke-sannsynlighetsprøve, satser du på et mangfoldig og representativt utvalg.
dine deltakere frivillig for undersøkelsen, noe som gjør dette til en ikke-sannsynlighetsprøve.
Beregn tilstrekkelig utvalgsstørrelse
før du rekrutterer deltakere, bestem deg for utvalgsstørrelsen enten ved å se på andre studier i ditt felt eller ved å bruke statistikk. En prøve som er for liten kan være representativ for prøven, mens en prøve som er for stor vil være dyrere enn nødvendig.
det er mange utvalgsstørrelseskalkulatorer online. Ulike formler brukes avhengig av om du har undergrupper eller hvor streng studien din skal være (f.eks. i klinisk forskning). Som en tommelfingerregel er minimum 30 enheter eller mer per undergruppe nødvendig.
for å bruke disse kalkulatorene må du forstå og skrive inn disse nøkkelkomponentene:
- Signifikansnivå (alfa): Risikoen for å avvise en sann nullhypotese som du er villig til å ta, vanligvis satt til 5%.
- Statistisk styrke: sannsynligheten for at studien din oppdager en effekt av en viss størrelse hvis det er en, vanligvis 80% eller høyere.
- Forventet effektstørrelse: en standardisert indikasjon på hvor stort forventet resultat av studien din vil være, vanligvis basert på andre lignende studier.
- Populasjonsstandardavvik: et estimat av populasjonsparameteren basert på en tidligere studie eller en egen pilotstudie.

Trinn 3: Oppsummer dataene dine med beskrivende statistikk
når du har samlet alle dataene dine, kan du inspisere dem og beregne beskrivende statistikk som oppsummerer dem.
Inspiser dataene dine
det finnes ulike måter å inspisere dataene på, inkludert følgende:
- Organisere data fra hver variabel i frekvensfordelingstabeller.
- Vise data fra en nøkkelvariabel i et stolpediagram for å vise fordelingen av svar.
- Visualisere forholdet mellom to variabler ved hjelp av et punktdiagram.
ved å visualisere dataene dine i tabeller og grafer, kan du vurdere om dataene dine følger en skjev eller normal fordeling, og om det er noen avvik eller manglende data.
en normalfordeling betyr at dataene dine er symmetrisk fordelt rundt et senter der de fleste verdier ligger, med verdiene avsmalnende ved haleendene.
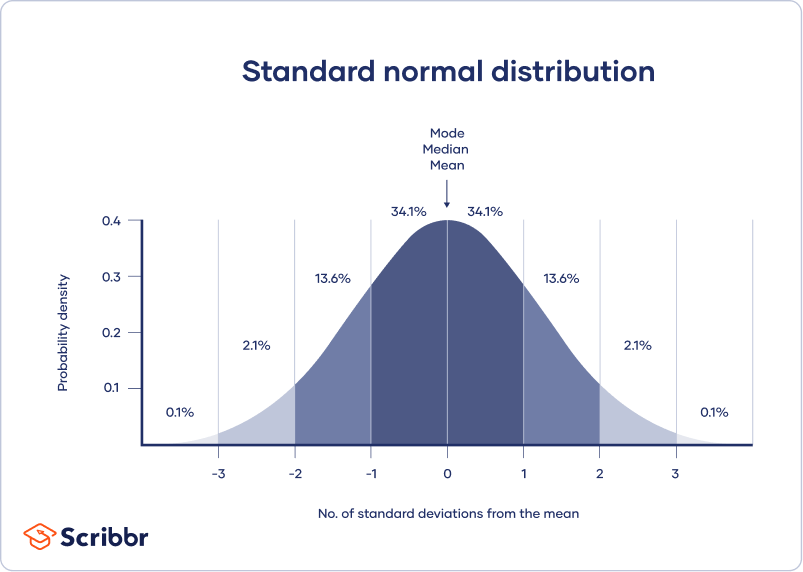
i kontrast er en skjevfordeling asymmetrisk og har flere verdier i den ene enden enn den andre. Formen på fordelingen er viktig å huske på fordi bare noen beskrivende statistikk skal brukes med skjeve distribusjoner.
Ekstreme uteliggere kan også produsere villedende statistikk, så du kan trenge en systematisk tilnærming til å håndtere disse verdiene.
Beregn mål av sentral tendens
Mål av sentral tendens beskriver hvor de fleste verdiene i et datasett ligger. Tre hovedmålinger av sentral tendens rapporteres ofte:
- Modus: det mest populære svaret eller verdien i datasettet.
- Median: verdien i nøyaktig midten av datasettet når bestilt fra lav til høy.
- Gjennomsnitt: summen av alle verdier dividert med antall verdier.
men avhengig av formen på fordelingen og målenivået, kan bare ett eller to av disse tiltakene være hensiktsmessige. For eksempel kan mange demografiske egenskaper bare beskrives ved hjelp av modusen eller proporsjonene, mens en variabel som reaksjonstid kanskje ikke har en modus i det hele tatt.
Beregn mål av variabilitet
Mål av variabilitet forteller deg hvor spredt verdiene i et datasett er. Fire hovedmålinger av variabilitet rapporteres ofte:
- Område: den høyeste verdien minus den laveste verdien av datasettet.
- Interkvartilt område: området for den midtre halvdelen av datasettet.
- Standardavvik: gjennomsnittlig avstand mellom hver verdi i datasettet og gjennomsnittet.
- Varians: kvadratet av standardavviket.
igjen bør formen på fordelingen og målenivået veilede ditt valg av variabilitetsstatistikk. Interkvartilområdet er det beste målet for skjevfordelinger, mens standardavvik og varians gir den beste informasjonen for normalfordelinger.
- Eksperimentell
- Korrelasjonell
ved å Bruke tabellen din, bør du sjekke om enhetene i beskrivende statistikk er sammenlignbare for pretest og posttest score. Er for eksempel variansnivåene like på tvers av gruppene? Er det noen ekstreme verdier? Hvis det er det, må du kanskje identifisere og fjerne ekstreme utliggere i datasettet eller transformere dataene dine før du utfører en statistisk test.
| Pretest score | posttest score | |
|---|---|---|
| Gjennomsnittlig | 68.44 | 75.25 |
| Standardavvik | 9.43 | 9.88 |
| Varians | 88.96 | 97.96 |
| Rekkevidde | 36.25 | 45.12 |
| N | 30 | |
Fra denne tabellen kan vi se at gjennomsnittlig poengsum økte etter meditasjonsøvelsen, og variansene til de to poengene er sammenlignbare. Deretter kan vi utføre en statistisk test for å finne ut om denne forbedringen i testresultater er statistisk signifikant i befolkningen.
det er viktig å sjekke om du har et bredt spekter av datapunkter. Hvis du ikke gjør det, kan dataene dine være skjev mot noen grupper mer enn andre (f.eks. høye akademiske achievers), og bare begrensede konklusjoner kan gjøres om et forhold.
| Foreldrenes inntekt (USD) | GPA | |
|---|---|---|
| Gjennomsnittlig | 62,100 | 3.12 |
| Standardavvik | 15,000 | 0.45 |
| Varians | 225,000,000 | 0.16 |
| Rekkevidde | 8,000–378,000 | 2.64–4.00 |
| N | 653 | |
Deretter kan vi beregne en korrelasjonskoeffisient og utføre en statistisk test for å forstå betydningen av forholdet mellom variablene i befolkningen.
Trinn 4: Test hypoteser eller lag estimater med inferensiell statistikk
et tall som beskriver et utvalg kalles en statistikk, mens et tall som beskriver en populasjon kalles en parameter. Ved hjelp av inferensiell statistikk kan du trekke konklusjoner om befolkningsparametere basert på utvalgsstatistikk.
Forskere bruker ofte to hovedmetoder (samtidig) for å gjøre avledninger i statistikk.
- Estimering: beregning av populasjonsparametere basert på utvalgsstatistikk.
- Hypotesetesting: en formell prosess for testing av forskningspådommer om befolkningen ved hjelp av prøver.
Estimering
du kan lage to typer estimater av populasjonsparametere fra utvalgsstatistikk:
- et punktestimat: en verdi som representerer din beste gjetning av den eksakte parameteren.
- et intervall estimat: en rekke verdier som representerer din beste gjetning av hvor parameteren ligger.
hvis målet ditt er å utlede og rapportere populasjonsegenskaper fra eksempeldata, er det best å bruke både punkt-og intervallestimater i papiret.
du kan vurdere en utvalgsstatistikk et punktestimat for befolkningsparameteren når du har et representativt utvalg (for eksempel i en bred offentlig meningsmåling blir andelen av et utvalg som støtter den nåværende regjeringen tatt som befolkningsandelen av regjeringens støttespillere).
det er alltid feil involvert i estimering, så du bør også gi et konfidensintervall som et intervallestimat for å vise variabiliteten rundt et punktestimat.
et konfidensintervall bruker standardfeilen og z-poengsummen fra standard normalfordelingen for å formidle hvor du vanligvis forventer å finne populasjonsparameteren mesteparten av tiden.
Hypotesetesting
Ved hjelp av data fra et utvalg kan du teste hypoteser om forhold mellom variabler i populasjonen. Hypotesetesting starter med antagelsen om at nullhypotesen er sann i befolkningen, og du bruker statistiske tester for å vurdere om nullhypotesen kan avvises eller ikke.
Statistiske tester bestemmer hvor utvalgsdataene dine vil ligge på en forventet fordeling av utvalgsdata hvis nullhypotesen var sann. Disse testene gir to hovedutganger:
- en teststatistikk forteller deg hvor mye dataene dine skiller seg fra nullhypotesen til testen.
- En p-verdi forteller deg sannsynligheten for å oppnå resultatene dine hvis nullhypotesen faktisk er sant i befolkningen.
Statistiske tester kommer i tre hovedvarianter:
- Sammenligningstester vurderer gruppeforskjeller i utfall.
- Regresjonstester vurderer årsakssammenheng mellom variabler.
- Korrelasjonstester vurderer sammenhenger mellom variabler uten å anta årsakssammenheng.
ditt valg av statistisk test avhenger av dine forskningsspørsmål, forskningsdesign, prøvetakingsmetode og dataegenskaper.
Parametriske tester
Parametriske tester gjør kraftige slutninger om befolkningen basert på prøvedata. Men for å bruke dem må noen forutsetninger oppfylles, og bare enkelte typer variabler kan brukes. Hvis dataene dine bryter med disse forutsetningene, kan du utføre passende datatransformasjoner eller bruke alternative ikke-parametriske tester i stedet.
en regresjonsmodellerer i hvilken grad endringer i en prediktorvariabel resulterer i endringer i utfallsvariabel(er).
- en enkel lineær regresjon inkluderer en prediktorvariabel og en utfallsvariabel.
- en multippel lineær regresjon inkluderer to eller flere prediktorvariabler og en utfallsvariabel.
Sammenligningstester sammenligner vanligvis middelene til grupper. Disse kan være middel for forskjellige grupper i et utvalg (f.eks. en behandlings-og kontrollgruppe), middel for en utvalgsgruppe tatt på forskjellige tidspunkter (f. eks. pretest-og posttest-score), eller et utvalgsgjennomsnitt og et populasjonsgjennomsnitt.
- En t-test er for nøyaktig 1 eller 2 grupper når prøven er liten (30 eller mindre).
- en z-test er for nøyaktig 1 eller 2 grupper når prøven er stor.
- En ANOVA er for 3 eller flere grupper.
z-og t-testene har undertyper basert på antall og typer prøver og hypotesene:
- hvis du bare har en prøve som du vil sammenligne med et populasjonsmiddel, bruker du en prøvetest.
- hvis du har sammenkoblede målinger (design innen emner), bruker du en avhengig (sammenkoblet) prøvetest.
- hvis du har helt separate målinger fra to uovertruffen grupper (mellom fagdesign), bruk en uavhengig prøvetest.
- hvis du forventer en forskjell mellom grupper i en bestemt retning, bruk en en-tailed test.
- hvis du ikke har noen forventninger til retningen av en forskjell mellom grupper, kan du bruke en to-tailed test.
Den eneste parametriske korrelasjonstesten er Pearsons r. korrelasjonskoeffisienten (r) forteller deg styrken av et lineært forhold mellom to kvantitative variabler.
men for å teste om korrelasjonen i utvalget er sterk nok til å være viktig i populasjonen, må du også utføre en signifikansprøve av korrelasjonskoeffisienten, vanligvis en t-test, for å oppnå en p-verdi. Denne testen bruker prøvestørrelsen til å beregne hvor mye korrelasjonskoeffisienten er forskjellig fra null i populasjonen.
- Eksperimentell
- Korrelasjonell
du bruker en avhengig-prøver, one-tailed t test for å vurdere om meditasjonsøvelsen betydelig forbedret matte testresultater. Testen gir deg:
- en t-verdi (teststatistikk) på 3,00
- en p-verdi av 0.0028
Selv Om Pearsons r er en teststatistikk, forteller Den deg ikke noe om hvor signifikant korrelasjonen er i befolkningen. Du må også teste om denne utvalgskorrelasjonskoeffisienten er stor nok til å demonstrere en korrelasjon i befolkningen.
En t-test kan også bestemme hvor signifikant en korrelasjonskoeffisient skiller seg fra null basert på utvalgsstørrelse. Siden du forventer en positiv sammenheng mellom foreldrenes inntekt og GPA, bruker du en en-prøve, en-tailed t-test. T-testen gir deg:
- en t-verdi på 3,08
- en p-verdi på 0.001
Trinn 5: Tolke resultatene
det siste trinnet i statistisk analyse er å tolke resultatene.
Statistisk signifikans
i hypotesetesting er statistisk signifikans hovedkriteriene for å danne konklusjoner. Du sammenligner p-verdien med et angitt signifikansnivå (vanligvis 0,05) for å avgjøre om resultatene er statistisk signifikante eller ikke-signifikante.
Statistisk signifikante resultater anses usannsynlig å ha oppstått utelukkende på grunn av tilfeldighet. Det er bare en svært lav sjanse for at et slikt resultat oppstår hvis nullhypotesen er sant i befolkningen.
- Eksperimentell
- Korrelasjonell
dette betyr at du tror at meditasjonsintervensjonen, i stedet for tilfeldige faktorer, direkte forårsaket økningen i testresultater.
merk at korrelasjon ikke alltid betyr årsakssammenheng, fordi det ofte er mange underliggende faktorer som bidrar til en kompleks variabel som GPA. Selv om en variabel er relatert til en annen, kan dette skyldes at en tredje variabel påvirker begge, eller indirekte koblinger mellom de to variablene.
en stor utvalgsstørrelse kan også sterkt påvirke den statistiske signifikansen av en korrelasjonskoeffisient ved å gjøre svært små korrelasjonskoeffisienter synes signifikante.
Effektstørrelse
et statistisk signifikant resultat betyr ikke nødvendigvis at det er viktige virkelige applikasjoner eller kliniske resultater for et funn.
derimot angir effektstørrelsen den praktiske betydningen av resultatene dine. Det er viktig å rapportere effektstørrelser sammen med inferensiell statistikk for et komplett bilde av resultatene. Du bør også rapportere intervallestimater av effektstørrelser hvis du skriver ET APA-stilpapir.
- Eksperimentell
- Korrelasjonell
Med En Cohens d på 0.72, det er middels til høy praktisk betydning for å finne ut at meditasjonsøvelsen forbedret testresultater.
fordi verdien din er mellom 0,1 og 0,3, representerer ditt funn av forhold mellom foreldreinntekt og GPA en svært liten effekt og har begrenset praktisk betydning.
Beslutningsfeil
Type i-OG TYPE II-feil er feil gjort i forskningskonklusjoner. En type i-feil betyr å avvise nullhypotesen når den faktisk er sann, mens En TYPE II-feil betyr at du ikke avviser nullhypotesen når den er falsk.
du kan sikte på å minimere risikoen for disse feilene ved å velge et optimalt signifikansnivå og sikre høy effekt. Det er imidlertid en avveining mellom de to feilene, så en fin balanse er nødvendig.
Frequentist versus Bayesiansk statistikk
tradisjonelt vektlegger frequentist statistikk nullhypotese signifikans testing og starter alltid med antagelsen om en sann nullhypotese.
Imidlertid Har Bayesiansk statistikk vokst i popularitet som en alternativ tilnærming de siste tiårene. I denne tilnærmingen bruker du tidligere forskning for å kontinuerlig oppdatere hypotesene dine basert på dine forventninger og observasjoner.
Bayes-faktor sammenligner den relative styrken av bevis for null versus den alternative hypotesen i stedet for å konkludere om å avvise nullhypotesen eller ikke.
Ofte stilte spørsmål om statistisk analyse
Statistisk analyse er den viktigste metoden for å analysere kvantitative forskningsdata. Den bruker sannsynligheter og modeller for å teste spådommer om en populasjon fra utvalgsdata.
Beskrivende statistikk oppsummerer egenskapene til et datasett. Inferensiell statistikk lar deg teste en hypotese eller vurdere om dataene dine kan generaliseres til den bredere befolkningen.
Hypotesetesting er en formell prosedyre for å undersøke våre ideer om verden ved hjelp av statistikk. Det brukes av forskere til å teste spesifikke spådommer, kalt hypoteser, ved å beregne hvor sannsynlig det er at et mønster eller forhold mellom variabler kunne ha oppstått ved en tilfeldighet.
i statistisk hypotesetesting forutsier nullhypotesen til en test alltid ingen effekt eller ingen sammenheng mellom variabler, mens den alternative hypotesen angir din forskningsprognose av en effekt eller forhold.
Statistisk signifikans Er et begrep som brukes av forskere for å si at det er usannsynlig at deres observasjoner kunne ha skjedd under nullhypotesen til en statistisk test. Signifikans er vanligvis betegnet med en p-verdi eller sannsynlighetsverdi.
Statistisk signifikans er vilkårlig-det avhenger av terskelen, eller alfa-verdien, valgt av forskeren. Den vanligste terskelen er p < 0,05, noe som betyr at dataene sannsynligvis vil forekomme mindre enn 5% av tiden under nullhypotesen.
når p-verdien faller under den valgte alfa-verdien, sier vi at resultatet av testen er statistisk signifikant.