analiza statistică înseamnă investigarea tendințelor, modelelor și relațiilor folosind date cantitative. Este un instrument important de cercetare folosit de oameni de știință, guverne, întreprinderi și alte organizații.
pentru a trage concluzii valide, analiza statistică necesită o planificare atentă încă de la începutul procesului de cercetare. Trebuie să specificați ipotezele dvs. și să luați decizii cu privire la proiectarea cercetării, dimensiunea eșantionului și procedura de eșantionare.
după colectarea datelor din eșantionul dvs., puteți organiza și rezuma datele folosind statistici descriptive. Apoi, puteți utiliza statistici inferențiale pentru a testa formal ipotezele și a face estimări despre populație. În cele din urmă, puteți interpreta și generaliza constatările dvs.
acest articol este o introducere practică în analiza statistică pentru studenți și cercetători. Vă vom parcurge pașii folosind două exemple de cercetare. Primul investighează o potențială relație cauză-efect, în timp ce al doilea investighează o potențială corelație între variabile.
Pasul 1: Scrieți-vă ipotezele și planificați-vă designul de cercetare
pentru a colecta date valide pentru analiza statistică, trebuie mai întâi să specificați ipotezele și să vă planificați designul de cercetare.
scrierea ipotezelor statistice
scopul cercetării este adesea de a investiga o relație între variabilele din cadrul unei populații. Începeți cu o predicție și utilizați analiza statistică pentru a testa acea predicție.
o ipoteză statistică este un mod formal de a scrie o predicție despre o populație. Fiecare predicție de cercetare este reformulată în ipoteze nule și alternative care pot fi testate folosind date eșantion.
în timp ce ipoteza nulă prezice întotdeauna nici un efect sau nici o relație între variabile, ipoteza alternativă afirmă predicția dvs. de cercetare a unui efect sau relație.
- ipoteză nulă: un exercițiu de meditație de 5 minute nu va avea niciun efect asupra scorurilor testelor de matematică la adolescenți.
- ipoteză alternativă: un exercițiu de meditație de 5 minute va îmbunătăți scorurile testelor de matematică la adolescenți.
- ipoteză nulă: venitul Parental și GPA nu au nicio relație între ele la studenți.
- ipoteză alternativă: venitul Parental și GPA sunt corelate pozitiv la studenți.
planificarea designului de cercetare
un design de cercetare este strategia dvs. generală pentru colectarea și analiza datelor. Acesta determină testele statistice pe care le puteți utiliza pentru a testa ipoteza dvs. mai târziu.
în primul rând, decideți dacă cercetarea dvs. va utiliza un design descriptiv, corelațional sau experimental. Experimentele influențează direct variabilele, în timp ce studiile descriptive și corelaționale măsoară doar variabilele.
- într-un design experimental, puteți evalua o relație cauză-efect (de exemplu, efectul meditației asupra scorurilor testelor) folosind teste statistice de comparație sau regresie.
- într-un design corelațional, puteți explora relațiile dintre variabile (de ex., venitul parental și GPA) fără nicio presupunere de cauzalitate folosind coeficienți de corelație și teste de semnificație.
- într-un design descriptiv, puteți studia caracteristicile unei populații sau a unui fenomen (de exemplu, prevalența anxietății la studenții din SUA) folosind teste statistice pentru a trage inferențe din datele eșantionului.
proiectul dvs. de cercetare se referă, de asemenea, dacă veți compara participanții la nivel de grup sau la nivel individual sau ambele.
- într-un design între subiecți, comparați rezultatele la nivel de grup ale participanților care au fost expuși la diferite tratamente (de exemplu, cei care au efectuat un exercițiu de meditație față de cei care nu au făcut-o).
- într-un design în cadrul subiecților, comparați măsurile repetate de la participanții care au participat la toate tratamentele unui studiu (de exemplu, scoruri înainte și după efectuarea unui exercițiu de meditație).
- Experimental
- Corelațional
în primul rând, veți lua scorurile testelor de bază de la participanți. Apoi, participanții dvs. vor fi supuși unui exercițiu de meditație de 5 minute. În cele din urmă, veți înregistra scorurile participanților la un al doilea test de matematică.
în acest experiment, variabila independentă este exercițiul de meditație de 5 minute, iar variabila dependentă este schimbarea scorurilor testelor de matematică înainte și după intervenție.
nu există variabile dependente sau independente în acest studiu, deoarece doriți doar să măsurați variabilele fără a le influența în niciun fel.
măsurarea variabilelor
când planificați un design de cercetare, ar trebui să operaționalizați variabilele și să decideți exact cum le veți măsura.
pentru analiza statistică, este important să luați în considerare nivelul de măsurare a variabilelor dvs., care vă spune ce fel de date conțin:
- datele categorice reprezintă grupări. Acestea pot fi nominale (de ex. gen) sau ordinal (de exemplu, nivelul capacității lingvistice).
- datele cantitative reprezintă sume. Acestea pot fi pe o scală de interval (de exemplu, scorul testului) sau pe o scală de raport (de exemplu, vârsta).
multe variabile pot fi măsurate la diferite niveluri de precizie. De exemplu, datele de vârstă pot fi cantitative (8 ani) sau categorice (tinere). Dacă o variabilă este codificată numeric (de exemplu, nivelul de acord de la 1 la 5), nu înseamnă automat că este cantitativă în loc de categorică.
identificarea nivelului de măsurare este importantă pentru alegerea statisticilor adecvate și a testelor de ipoteză. De exemplu, puteți calcula un scor mediu cu date cantitative, dar nu cu date categorice.
într-un studiu de cercetare, împreună cu măsurile variabilelor dvs. de interes, veți colecta adesea date despre caracteristicile relevante ale participanților.
- Experimental
- Corelațional
| variabilă | tip de date |
|---|---|
| vârsta | cantitativă (raport) |
| gen | categoric (nominal) |
| rasă sau etnie | categorică (nominală) |
| scorurile testelor inițiale | cantitative (interval) |
| rezultatele finale ale testului | cantitative (interval) |
| variabilă | tip de date |
|---|---|
| venitul Parental | cantitativ (raport) |
| GPA | cantitativ (interval) |
Pasul 2: Colectați date dintr-un eșantion
în majoritatea cazurilor, este prea dificil sau costisitor să colectați date de la fiecare membru al populației pe care sunteți interesat să o studiați. În schimb, veți colecta date dintr-un eșantion.
analiza statistică vă permite să aplicați constatările dvs. dincolo de propriul eșantion, atâta timp cât utilizați proceduri de eșantionare adecvate. Ar trebui să vizați un eșantion reprezentativ pentru populație.
eșantionare pentru analiza statistică
există două abordări principale pentru selectarea unui eșantion.
- eșantionarea probabilității: fiecare membru al populației are șansa de a fi selectat pentru studiu prin selecție aleatorie.
- eșantionare non-probabilitate: unii membri ai populației sunt mai predispuși decât alții să fie selectați pentru studiu din cauza unor criterii precum comoditatea sau auto-selecția voluntară.
în teorie, pentru constatări foarte generalizabile, ar trebui să utilizați o metodă de eșantionare a probabilității. Selecția aleatorie reduce părtinirea eșantionării și se asigură că datele din eșantionul dvs. sunt de fapt tipice populației. Testele parametrice pot fi utilizate pentru a face inferențe statistice puternice atunci când datele sunt colectate folosind eșantionarea probabilității.
dar, în practică, rareori este posibil să se adune eșantionul ideal. În timp ce eșantioanele de non-probabilitate sunt mai susceptibile de a fi părtinitoare, acestea sunt mult mai ușor de recrutat și colectat date. Testele non-parametrice sunt mai potrivite pentru probele de non-probabilitate, dar au ca rezultat inferențe mai slabe despre populație.
dacă doriți să utilizați teste parametrice pentru eșantioane non-probabilitate, trebuie să faceți cazul în care:
- eșantionul dvs. este reprezentativ pentru populația la care generalizați constatările.
- eșantionul dvs. nu are părtinire sistematică.
rețineți că validitatea externă înseamnă că vă puteți generaliza concluziile doar altora care împărtășesc caracteristicile eșantionului dvs. De exemplu, rezultate din eșantioane occidentale, educate, industrializate, bogate și democratice (de ex., studenți din SUA) nu sunt aplicabile automat tuturor populațiilor non-ciudate.
dacă aplicați teste parametrice datelor din eșantioane de non-probabilitate, asigurați-vă că elaborați limitările cât de departe pot fi generalizate rezultatele dvs. în secțiunea de discuții.
creați o procedură de eșantionare adecvată
pe baza resurselor disponibile pentru cercetare, decideți cum veți recruta participanți.
- veți avea resurse pentru a vă promova studiul pe scară largă, inclusiv în afara cadrului universitar?
- veți avea mijloacele de a recruta un eșantion divers care reprezintă o populație largă?
- aveți timp să contactați și să urmăriți membrii grupurilor greu accesibile?
- Experimental
- corelațional
participanții dvs. sunt auto-selectați de școlile lor. Deși utilizați un eșantion de non-probabilitate, vă propuneți un eșantion divers și reprezentativ.
participanții dvs. se oferă voluntari pentru sondaj, făcând din acesta un eșantion non-probabilitate.
calculați dimensiunea suficientă a eșantionului
înainte de a recruta participanți, decideți dimensiunea eșantionului dvs. fie analizând alte studii din domeniul dvs., fie utilizând statistici. Un eșantion prea mic poate fi nereprezentativ pentru eșantion, în timp ce un eșantion prea mare va fi mai costisitor decât este necesar.
există mai multe calculatoare dimensiunea eșantionului on-line. Diferite formule sunt utilizate în funcție de faptul dacă aveți subgrupuri sau cât de riguros ar trebui să fie studiul dvs. (de exemplu, în cercetarea clinică). De regulă, este necesar un minim de 30 de unități sau mai mult pe subgrup.
pentru a utiliza aceste calculatoare, trebuie să înțelegeți și să introduceți aceste componente cheie:
- nivelul de semnificație (alfa): riscul de a respinge o adevărată ipoteză nulă pe care sunteți dispus să o luați, de obicei stabilită la 5%.
- puterea statistică: probabilitatea ca studiul dvs. să detecteze un efect de o anumită dimensiune dacă există unul, de obicei 80% sau mai mare.
- dimensiunea efectului așteptat: o indicație standardizată a cât de mare va fi rezultatul așteptat al studiului dvs., de obicei pe baza altor studii similare.
- deviația standard a populației: o estimare a parametrului populației pe baza unui studiu anterior sau a unui studiu pilot propriu.

Pasul 3: rezumați datele cu statistici descriptive
după ce ați colectat toate datele, le puteți inspecta și calcula statistici descriptive care le rezumă.
inspectați-vă datele
există diferite modalități de a vă inspecta datele, inclusiv următoarele:
- organizarea datelor din fiecare variabilă în tabelele de distribuție a frecvenței.
- afișarea datelor dintr-o variabilă cheie într-o diagramă cu bare pentru a vizualiza distribuția răspunsurilor.
- vizualizarea relației dintre două variabile folosind un grafic scatter.
vizualizând datele dvs. în tabele și grafice, puteți evalua dacă datele dvs. urmează o distribuție înclinată sau normală și dacă există valori aberante sau date lipsă.
o distribuție normală înseamnă că datele dvs. sunt distribuite simetric în jurul unui centru în care se află majoritatea valorilor, cu valorile care se micșorează la capetele cozii.
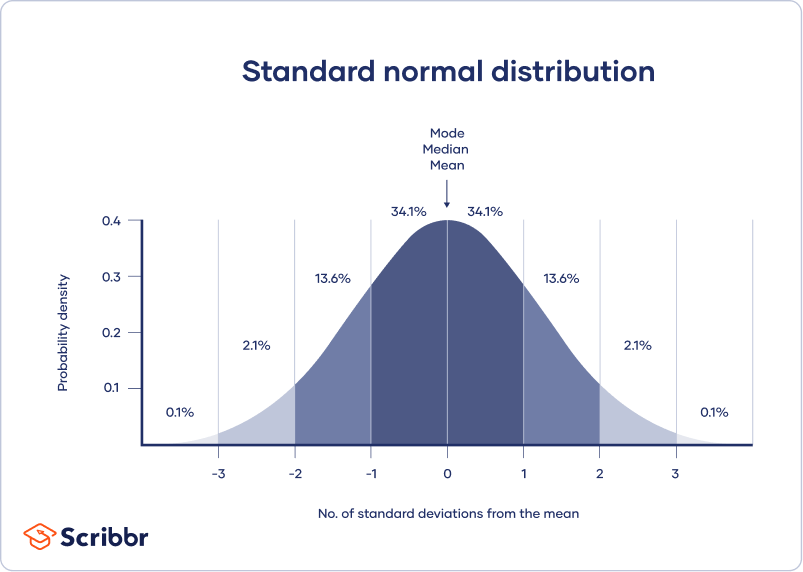
în schimb, o distribuție înclinată este asimetrică și are mai multe valori la un capăt decât la celălalt. Forma distribuției este importantă de reținut, deoarece numai unele statistici descriptive ar trebui utilizate cu distribuții înclinate.
valorile extreme pot produce, de asemenea, statistici înșelătoare, deci este posibil să aveți nevoie de o abordare sistematică pentru a trata aceste valori.
calculați măsurile tendinței centrale
măsurile tendinței centrale descriu unde se află majoritatea valorilor dintr-un set de date. Trei măsuri principale ale tendinței centrale sunt adesea raportate:
- mod: cel mai popular răspuns sau valoare din setul de date.
- mediană: valoarea în mijlocul exactă a setului de date atunci când a ordonat de la mic la mare.
- medie: suma tuturor valorilor împărțită la numărul de valori.
cu toate acestea, în funcție de forma distribuției și de nivelul de măsurare, numai una sau două dintre aceste măsuri pot fi adecvate. De exemplu, multe caracteristici demografice pot fi descrise doar folosind modul sau proporțiile, în timp ce o variabilă precum timpul de reacție poate să nu aibă deloc un mod.
calculați măsurile de variabilitate
măsurile de variabilitate vă spun cât de răspândite sunt valorile dintr-un set de date. Patru măsuri principale de variabilitate sunt adesea raportate:
- interval: cea mai mare valoare minus cea mai mică valoare a setului de date.
- interval Interquartile: intervalul jumătății medii a setului de date.
- deviație Standard: distanța medie dintre fiecare valoare din setul de date și medie.
- varianță: pătratul deviației standard.
încă o dată, forma distribuției și nivelul de măsurare ar trebui să vă ghideze alegerea statisticilor de variabilitate. Intervalul interquartil este cea mai bună măsură pentru distribuțiile înclinate, în timp ce deviația standard și varianța oferă cele mai bune informații pentru distribuțiile normale.
- Experimental
- corelațional
folosind tabelul dvs., ar trebui să verificați dacă unitățile statisticilor descriptive sunt comparabile pentru scorurile pretest și posttest. De exemplu, nivelurile de varianță sunt similare între grupuri? Există valori extreme? Dacă există, poate fi necesar să identificați și să eliminați valorile extreme din setul de date sau să vă transformați datele înainte de a efectua un test statistic.
| scoruri Pretest | scoruri Posttest | |
|---|---|---|
| medie | 68.44 | 75.25 |
| deviația Standard | 9.43 | 9.88 |
| varianță | 88.96 | 97.96 |
| gama | 36.25 | 45.12 |
| N | 30 | |
din acest tabel, putem vedea că Scorul mediu a crescut după exercițiul de meditație, iar varianțele celor două scoruri sunt comparabile. În continuare, putem efectua un test statistic pentru a afla dacă această îmbunătățire a scorurilor testelor este semnificativă statistic în populație.
este important să verificați dacă aveți o gamă largă de puncte de date. Dacă nu, datele dvs. pot fi înclinate către unele grupuri mai mult decât altele (de exemplu, cu rezultate academice ridicate) și se pot face doar deducții limitate despre o relație.
| venitul Parental (USD) | GPA | |
|---|---|---|
| medie | 62,100 | 3.12 |
| deviația Standard | 15,000 | 0.45 |
| varianță | 225,000,000 | 0.16 |
| gama | 8,000–378,000 | 2.64–4.00 |
| N | 653 | |
apoi, putem calcula un coeficient de corelație și putem efectua un test statistic pentru a înțelege semnificația relației dintre variabilele din populație.
Pasul 4: Testați ipoteze sau faceți estimări cu statistici inferențiale
un număr care descrie un eșantion se numește Statistică, în timp ce un număr care descrie o populație se numește parametru. Folosind statistici inferențiale, puteți face concluzii despre parametrii populației pe baza statisticilor eșantionului.
cercetătorii folosesc adesea două metode principale (simultan) pentru a face inferențe în statistici.
- estimare: calcularea parametrilor populației pe baza statisticilor eșantionului.
- Testarea ipotezelor: un proces formal pentru testarea predicțiilor de cercetare despre populație folosind probe.
estimare
puteți face două tipuri de estimări ale parametrilor populației din Statisticile eșantionului:
- o estimare punct: o valoare care reprezintă cea mai bună presupunere a parametrului exact.
- o estimare a intervalului: o gamă de valori care reprezintă cea mai bună estimare a locului în care se află parametrul.
dacă scopul dvs. este de a deduce și de a raporta caracteristicile populației din datele eșantionului, cel mai bine este să utilizați atât estimări punctuale, cât și intervale în lucrarea dvs.
puteți considera o statistică a eșantionului o estimare punctuală pentru parametrul populației atunci când aveți un eșantion reprezentativ (de exemplu, într-un sondaj larg de opinie publică, proporția unui eșantion care susține Guvernul actual este luată ca proporție a populației de susținători guvernamentali).
există întotdeauna eroare implicată în estimare, deci ar trebui să furnizați și un interval de încredere ca o estimare a intervalului pentru a arăta variabilitatea în jurul unei estimări punctuale.
un interval de încredere utilizează eroarea standard și scorul z din distribuția normală standard pentru a transmite unde vă așteptați în general să găsiți parametrul populație de cele mai multe ori.
Testarea ipotezelor
folosind date dintr-un eșantion, puteți testa ipoteze despre relațiile dintre variabilele din populație. Testarea ipotezelor începe cu presupunerea că ipoteza nulă este adevărată în populație și utilizați teste statistice pentru a evalua dacă ipoteza nulă poate fi respinsă sau nu.
testele statistice determină unde s-ar afla datele eșantionului dvs. pe o distribuție așteptată a datelor eșantionului dacă ipoteza nulă ar fi adevărată. Aceste teste oferă două ieșiri principale:
- o statistică de testare vă spune cât de mult diferă datele dvs. de ipoteza nulă a testului.
- o valoare p vă spune probabilitatea de a obține rezultatele dvs. dacă ipoteza nulă este de fapt adevărată în populație.
testele statistice vin în trei soiuri principale:
- testele de comparație evaluează diferențele de grup în rezultate.
- testele de regresie evaluează relațiile cauză-efect între variabile.
- testele de corelație evaluează relațiile dintre variabile fără a presupune cauzalitatea.
alegerea testului statistic depinde de întrebările dvs. de cercetare, de proiectarea cercetării, de metoda de eșantionare și de caracteristicile datelor.
teste parametrice
testele parametrice fac concluzii puternice despre populație pe baza datelor eșantionului. Dar pentru a le folosi, trebuie îndeplinite unele ipoteze și pot fi utilizate doar câteva tipuri de variabile. Dacă datele dvs. încalcă aceste ipoteze, puteți efectua transformări de date adecvate sau puteți utiliza în schimb teste alternative non-parametrice.
o regresie modelează măsura în care modificările unei variabile predictoare duc la modificări ale variabilei(variabilelor) de rezultat.
- o regresie liniară simplă include o variabilă predictor și o variabilă de rezultat.
- o regresie liniară multiplă include două sau mai multe variabile predictoare și o variabilă de rezultat.
testele de comparație compară de obicei mijloacele grupurilor. Acestea pot fi mijloacele diferitelor grupuri din cadrul unui eșantion (de exemplu, un grup de tratament și control), mijloacele unui grup de eșantion prelevat la momente diferite (de exemplu, scorurile pretest și posttest) sau o medie a eșantionului și o medie a populației.
- un test t este pentru exact 1 sau 2 grupe atunci când eșantionul este mic (30 sau mai puțin).
- un test z este pentru exact 1 sau 2 grupe atunci când eșantionul este mare.
- un ANOVA este pentru 3 sau mai multe grupuri.
testele z și t au subtipuri bazate pe numărul și tipurile de probe și ipoteze:
- dacă aveți un singur eșantion pe care doriți să îl comparați cu o medie a populației, utilizați un test cu un singur eșantion.
- dacă ați asociat măsurători (în cadrul-subiecți de proiectare), utilizați un test de probe dependente (asociat).
- dacă aveți măsurători complet separate de două grupuri de neegalat (design între subiecți), utilizați un test independent de eșantioane.
- dacă vă așteptați la o diferență între grupuri într-o anumită direcție, utilizați un test cu o singură coadă.
- dacă nu aveți așteptări cu privire la direcția unei diferențe între grupuri, utilizați un test cu două cozi.
singurul test de corelație parametrică este Pearson r. coeficientul de corelație (r) vă spune puterea unei relații liniare între două variabile cantitative.
cu toate acestea, pentru a testa dacă corelația din eșantion este suficient de puternică pentru a fi importantă în populație, trebuie să efectuați și un test de semnificație al coeficientului de corelație, de obicei un test t, pentru a obține o valoare P. Acest test utilizează dimensiunea eșantionului dvs. pentru a calcula cât de mult diferă coeficientul de corelație de zero în populație.
- Experimental
- corelațional
utilizați un dependent-Probe, one-tailed t test pentru a evalua dacă exercițiul de meditație îmbunătățit în mod semnificativ scoruri de testare matematica. Testul vă oferă:
- o valoare t (statistica testului) de 3,00
- o valoare p a 0.0028
deși r-ul lui Pearson este o statistică de testare, nu vă spune nimic despre cât de semnificativă este corelația în populație. De asemenea, trebuie să testați dacă acest coeficient de corelație a eșantionului este suficient de mare pentru a demonstra o corelație în populație.
un test t poate determina, de asemenea, cât de semnificativ diferă un coeficient de corelație de zero pe baza dimensiunii eșantionului. Deoarece vă așteptați la o corelație pozitivă între venitul parental și GPA, utilizați un test T cu un singur eșantion. Testul t vă oferă:
- o valoare t de 3,08
- o valoare p de 0.001
Pasul 5: Interpretați rezultatele
ultimul pas al analizei statistice este interpretarea rezultatelor.
semnificație statistică
în testarea ipotezelor, semnificația statistică este principalul criteriu pentru formarea concluziilor. Comparați valoarea p cu un nivel de semnificație stabilit (de obicei 0,05) pentru a decide dacă rezultatele dvs. sunt semnificative statistic sau nesemnificative.
se consideră că este puțin probabil ca rezultatele semnificative statistic să fi apărut doar din întâmplare. Există doar o șansă foarte mică ca un astfel de rezultat să apară dacă ipoteza nulă este adevărată în populație.
- Experimental
- corelațional
aceasta înseamnă că credeți că intervenția meditației, mai degrabă decât factorii aleatorii, a provocat direct creșterea scorurilor testelor.
rețineți că corelația nu înseamnă întotdeauna cauzalitate, deoarece există adesea mulți factori care stau la baza unei variabile complexe precum GPA. Chiar dacă o variabilă este legată de alta, aceasta se poate datora unei a treia variabile care le influențează pe ambele sau legăturilor indirecte dintre cele două variabile.
o dimensiune mare a eșantionului poate, de asemenea, să influențeze puternic semnificația statistică a unui coeficient de corelație, făcând coeficienții de corelație foarte mici să pară semnificativi.
dimensiunea efectului
un rezultat semnificativ statistic nu înseamnă neapărat că există aplicații importante din viața reală sau rezultate clinice pentru o constatare.
în schimb, dimensiunea efectului indică semnificația practică a rezultatelor dvs. Este important să raportați dimensiunile efectului împreună cu statisticile inferențiale pentru o imagine completă a rezultatelor. De asemenea, ar trebui să raportați estimările intervalului dimensiunilor efectului dacă scrieți o hârtie în stil APA.
- Experimental
- corelațional
cu un Cohen ‘ S d de 0.72, există o semnificație practică medie până la mare pentru constatarea dvs. că exercițiul de meditație a îmbunătățit scorurile testelor.
deoarece valoarea dvs. este cuprinsă între 0,1 și 0,3, constatarea unei relații între venitul parental și GPA reprezintă un efect foarte mic și are o semnificație practică limitată.
erorile de decizie
erorile de tip I și de tip II sunt greșeli făcute în concluziile cercetării. O eroare de tip I înseamnă respingerea ipotezei nule atunci când este de fapt adevărată, în timp ce o eroare de tip II înseamnă eșecul respingerii ipotezei nule atunci când este falsă.
puteți încerca să minimalizați riscul acestor erori selectând un nivel optim de semnificație și asigurând o putere mare. Cu toate acestea, există un compromis între cele două erori, deci este necesar un echilibru fin.
Frequentist versus Bayesian statistics
în mod tradițional, frequentist statistics subliniază testarea semnificației ipotezei nule și începe întotdeauna cu presupunerea unei adevărate ipoteze nule.
cu toate acestea, statisticile Bayesiene au crescut în popularitate ca abordare alternativă în ultimele decenii. În această abordare, utilizați cercetările anterioare pentru a vă actualiza continuu ipotezele pe baza așteptărilor și observațiilor dvs.
factorul Bayes compară puterea relativă a dovezilor pentru nul față de ipoteza alternativă, mai degrabă decât să facă o concluzie cu privire la respingerea ipotezei nule sau nu.
Întrebări frecvente despre analiza statistică
analiza statistică este principala metodă de analiză a datelor cantitative de cercetare. Utilizează probabilități și modele pentru a testa predicțiile despre o populație din datele eșantionului.
statisticile Descriptive rezumă caracteristicile unui set de date. Statisticile inferențiale vă permit să testați o ipoteză sau să evaluați dacă datele dvs. sunt generalizabile pentru populația mai largă.
Testarea ipotezelor este o procedură formală pentru investigarea ideilor noastre despre lume folosind statistici. Este folosit de oamenii de știință pentru a testa predicții specifice, numite ipoteze, calculând cât de probabil este ca un model sau o relație între variabile să fi apărut întâmplător.
în testarea ipotezelor statistice, ipoteza nulă a unui test nu prezice întotdeauna niciun efect sau nicio relație între variabile, în timp ce ipoteza alternativă afirmă predicția dvs. de cercetare a unui efect sau relație.
semnificația statistică este un termen folosit de cercetători pentru a afirma că este puțin probabil ca observațiile lor să fi avut loc sub ipoteza nulă a unui test statistic. Semnificația este de obicei notată printr-o valoare p sau o valoare de probabilitate.
semnificația statistică este arbitrară-depinde de pragul sau valoarea alfa aleasă de cercetător. Cel mai frecvent prag este p < 0,05, ceea ce înseamnă că datele sunt susceptibile să apară mai puțin de 5% din timp sub ipoteza nulă.
când valoarea p scade sub valoarea alfa aleasă, atunci spunem că rezultatul testului este semnificativ statistic.