a statisztikai elemzés azt jelenti, hogy a trendeket, mintákat és kapcsolatokat kvantitatív adatok felhasználásával vizsgáljuk. Ez egy fontos kutatási eszköz, amelyet tudósok, kormányok, vállalkozások és más szervezetek használnak.
az érvényes következtetések levonásához a statisztikai elemzés gondos tervezést igényel a kutatási folyamat kezdetétől. Meg kell adnia hipotéziseit, és döntéseket kell hoznia a kutatási tervről, a minta méretéről és a mintavételi eljárásról.
miután adatokat gyűjtött a mintából, leíró statisztikák segítségével rendszerezheti és összegezheti az adatokat. Ezután következtetési statisztikákat használhat a hipotézisek hivatalos tesztelésére és a populációra vonatkozó becslések készítésére. Végül értelmezheti és általánosíthatja megállapításait.
ez a cikk gyakorlati bevezetés a statisztikai elemzés a diákok és a kutatók. Két kutatási példa segítségével végigvezetjük a lépéseket. Az első a lehetséges ok-okozati összefüggést vizsgálja, míg a második a változók közötti potenciális korrelációt vizsgálja.
1. lépés: Írja meg hipotéziseit és tervezze meg kutatási tervét
a statisztikai elemzéshez érvényes adatok gyűjtéséhez először meg kell adnia hipotéziseit, és meg kell terveznie a kutatási tervet.
statisztikai hipotézisek írása
a kutatás célja gyakran a populáción belüli változók közötti kapcsolat vizsgálata. Egy előrejelzéssel kezdi, és statisztikai elemzéssel teszteli ezt az előrejelzést.
a statisztikai hipotézis a populációra vonatkozó előrejelzés hivatalos módja. Minden kutatási előrejelzést null és alternatív hipotézisekké alakítanak át, amelyeket mintaadatok segítségével lehet tesztelni.
míg a nullhipotézis mindig nem jósol hatást vagy összefüggést a változók között, az alternatív hipotézis kimondja a hatás vagy kapcsolat kutatási előrejelzését.
- nullhipotézis: az 5 perces meditációs gyakorlatnak nincs hatása a tizenévesek matematikai teszteredményeire.
- alternatív hipotézis: egy 5 perces meditációs gyakorlat javítja a tizenévesek matematikai teszteredményeit.
- nullhipotézis: a szülői jövedelem és a GPA nincs kapcsolatban egymással a főiskolai hallgatókban.
- alternatív hipotézis: a szülői jövedelem és a GPA pozitívan korrelál a főiskolai hallgatókban.
a kutatási terv tervezése
a kutatási terv az adatgyűjtés és elemzés átfogó stratégiája. Meghatározza azokat a statisztikai teszteket, amelyekkel később tesztelheti hipotézisét.
először döntse el, hogy kutatása leíró, korrelációs vagy kísérleti tervet fog-e használni. A kísérletek közvetlenül befolyásolják a változókat, míg a leíró és korrelációs vizsgálatok csak a változókat mérik.
- egy kísérleti tervben felmérheti az ok-okozati összefüggést (például a meditáció hatását a teszt pontszámokra) az összehasonlítás vagy a regresszió statisztikai tesztjeivel.
- egy korrelációs tervben felfedezheti a változók közötti kapcsolatokat (pl., szülői jövedelem és GPA) a korrelációs együtthatók és szignifikancia tesztek alkalmazásával az ok-okozati összefüggés feltételezése nélkül.
- leíró kialakításban tanulmányozhatja egy populáció vagy jelenség jellemzőit (például a szorongás prevalenciáját az amerikai főiskolai hallgatókban) statisztikai tesztek segítségével, hogy következtetéseket vonjon le a mintaadatokból.
a kutatási terv arra is vonatkozik, hogy összehasonlítja-e a résztvevőket csoportszinten vagy egyéni szinten, vagy mindkettőt.
- az alanyok közötti kialakításban összehasonlítja a különböző kezeléseknek kitett résztvevők csoportszintű eredményeit (pl. azok, akik meditációs gyakorlatot végeztek, szemben azokkal, akik nem).
- a tantárgyakon belüli kialakításban összehasonlítja a résztvevők ismételt méréseit, akik részt vettek egy vizsgálat minden kezelésében (pl. a meditációs gyakorlat elvégzése előtt és után).
- Kísérleti
- Korrelációs
először a résztvevők kiindulási teszteredményeit veszi figyelembe. Ezután a résztvevők 5 perces meditációs gyakorlaton vesznek részt. Végül rögzíti a résztvevők pontszámait egy második matematikai tesztből.
ebben a kísérletben a független változó az 5 perces meditációs gyakorlat, a függő változó pedig a matematikai teszt pontszámainak változása a beavatkozás előtt és után.
ebben a tanulmányban nincsenek függő vagy független változók, mert csak a változókat akarja mérni anélkül, hogy bármilyen módon befolyásolná őket.
mérési változók
kutatási terv tervezésekor operacionalizálnia kell a változókat, és pontosan el kell döntenie, hogyan fogja mérni őket.
a statisztikai elemzéshez fontos figyelembe venni a változók mérési szintjét, amely megmondja, hogy milyen adatokat tartalmaznak:
- a kategorikus adatok csoportosulásokat képviselnek. Ezek lehetnek névlegesek (pl., nem) vagy ordinális (pl. nyelvi képesség szintje).
- a mennyiségi adatok mennyiségeket jelentenek. Ezek lehetnek intervallum skálán (pl. teszt pontszám) vagy Arány skálán (pl. életkor).
számos változó mérhető különböző pontossági szinteken. Például az életkori adatok lehetnek kvantitatívak (8 évesek) vagy kategorikusak (fiatalok). Ha egy változót numerikusan kódolnak (például az egyetértés szintje 1-5 között), ez nem jelenti automatikusan azt, hogy kvantitatív, nem pedig kategorikus.
a mérési szint meghatározása fontos a megfelelő statisztikai és hipotézisvizsgálatok kiválasztásához. Például kiszámíthatja az átlagos pontszámot kvantitatív adatokkal, de nem kategorikus adatokkal.
egy kutatási tanulmányban az érdeklődésre számot tartó változók mérésével együtt gyakran gyűjt adatokat a releváns résztvevők jellemzőiről.
- Kísérleti
- Korrelációs
| változó az adatok típusa | |
|---|---|
| életkor | mennyiségi (arány) |
| nem | kategorikus (névleges) |
| faj vagy etnikum | kategorikus (névleges) |
| kiindulási teszt pontszámok | kvantitatív (intervallum) |
| végső teszteredmények | kvantitatív (intervallum) |
| változó az adatok típusa | |
|---|---|
| szülői jövedelem | mennyiségi (arány) |
| GPA | mennyiségi (intervallum) |
2. lépés: Gyűjtsön adatokat egy mintából
a legtöbb esetben túl nehéz vagy drága adatokat gyűjteni a népesség minden tagjától, akit érdekel a tanulás. Ehelyett egy mintából gyűjt adatokat.
a statisztikai elemzés lehetővé teszi, hogy eredményeit a saját mintáján túl is alkalmazza, amennyiben megfelelő mintavételi eljárásokat alkalmaz. Olyan mintára kell törekednie, amely reprezentatív a lakosság számára.
mintavétel statisztikai elemzéshez
a minta kiválasztásának két fő megközelítése van.
- valószínűségi mintavétel: a populáció minden tagjának esélye van arra, hogy véletlenszerű szelekcióval kiválasszák a vizsgálatba.
- nem valószínűségi mintavétel: a populáció egyes tagjai nagyobb valószínűséggel kerülnek kiválasztásra a vizsgálatba olyan kritériumok miatt, mint a kényelem vagy az önkéntes önválasztás.
elméletileg a nagyon általánosítható eredményekhez valószínűségi mintavételi módszert kell használni. A véletlenszerű kiválasztás csökkenti a mintavételi torzítást, és biztosítja, hogy a mintából származó adatok valóban jellemzőek legyenek a sokaságra. A parametrikus tesztek felhasználhatók erős statisztikai következtetések levonására, amikor az adatokat valószínűségi mintavétel segítségével gyűjtik.
de a gyakorlatban ritkán lehetséges az ideális minta összegyűjtése. Míg a nem valószínűségi minták nagyobb valószínűséggel elfogultak,sokkal könnyebb toborozni és adatokat gyűjteni. A nem paraméteres tesztek megfelelőbbek a nem valószínűségi mintákhoz, de gyengébb következtetéseket eredményeznek a populációról.
ha parametrikus teszteket szeretne használni a nem valószínűségi mintákhoz, akkor meg kell tennie az esetet:
- a minta reprezentálja azt a populációt, amelyre általánosítja a megállapításait.
- a mintában nincs szisztematikus elfogultság.
ne feledje, hogy a külső érvényesség azt jelenti, hogy következtetéseit csak olyanokra általánosíthatja, akik osztják a minta jellemzőit. Például nyugati, művelt, iparosodott, gazdag és demokratikus minták eredményei (pl., főiskolai hallgatók az Egyesült Államokban) nem alkalmazhatók automatikusan az összes nem furcsa populációra.
ha paraméteres teszteket alkalmaz a nem valószínűségi mintákból származó adatokra, feltétlenül részletezze a vita szakaszban az eredmények általánosításának korlátait.
hozzon létre egy megfelelő mintavételi eljárást
a kutatáshoz rendelkezésre álló erőforrások alapján döntse el, hogyan toboroz résztvevőket.
- lesz források reklámozni a tanulmány széles körben, beleértve kívül az egyetemi környezetben?
- lesz-e eszköze egy változatos minta felvételére, amely széles népességet képvisel?
- van ideje kapcsolatba lépni és nyomon követni a nehezen elérhető csoportok tagjait?
- kísérleti
- korrelációs
a résztvevőket saját iskolájuk választja ki. Bár nem valószínűségi mintát használ, változatos és reprezentatív mintára törekszik.
a résztvevők önként jelentkeznek a felmérésre, így ez nem valószínűségi minta.
Számítsa ki a megfelelő mintaméretet
a résztvevők toborzása előtt döntse el a minta méretét vagy a szakterületen végzett egyéb tanulmányok áttekintésével, vagy statisztikák felhasználásával. Lehet, hogy a túl kicsi minta nem képviseli a mintát, míg a túl nagy minta a szükségesnél költségesebb lesz.
sok minta méretű számológépek online. Különböző képleteket használnak attól függően, hogy vannak-e alcsoportjai, vagy mennyire szigorúnak kell lennie a vizsgálatnak (pl. Hüvelykujjszabályként alcsoportonként legalább 30 egység vagy annál több szükséges.
ezeknek a számológépeknek a használatához meg kell értenie és be kell írnia ezeket a kulcsfontosságú összetevőket:
- szignifikancia szint (alfa): a valódi nullhipotézis elutasításának kockázata, amelyet hajlandó megtenni, általában 5% – ra állítva.
- statisztikai teljesítmény: annak a valószínűsége, hogy tanulmánya egy bizonyos méretű hatást észlel, ha van ilyen, általában 80% vagy annál magasabb.
- várható hatásméret: szabványosított jelzés arról, hogy mekkora lesz a vizsgálat várható eredménye, általában más hasonló vizsgálatok alapján.
- populációs szórás: a populációs paraméter becslése egy korábbi tanulmány vagy egy saját kísérleti tanulmány alapján.

3. lépés: összegezze adatait leíró statisztikákkal
miután összegyűjtötte az összes adatot, megvizsgálhatja őket, és kiszámíthatja azokat a leíró statisztikákat, amelyek összefoglalják őket.
ellenőrizze adatait
az adatok ellenőrzésének különféle módjai vannak, beleértve a következőket:
- adatok rendszerezése az egyes változókból a frekvenciaelosztási táblákban.
- egy kulcsváltozó adatainak megjelenítése egy oszlopdiagramban a válaszok eloszlásának megtekintéséhez.
- két változó közötti kapcsolat megjelenítése szórási diagram segítségével.
az adatok táblázatokban és grafikonokban történő megjelenítésével felmérheti, hogy az adatok ferde vagy normál eloszlást követnek-e, és vannak-e kiugró vagy hiányzó adatok.
a normál eloszlás azt jelenti, hogy az adatok szimmetrikusan oszlanak el egy olyan központ körül, ahol a legtöbb érték fekszik, az értékek a farok végén elvékonyodnak.
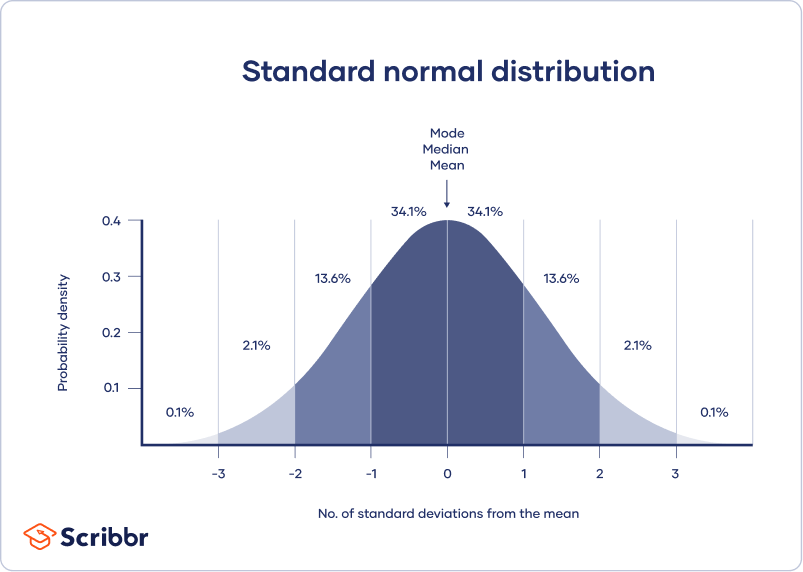
ezzel szemben a ferde Eloszlás aszimmetrikus, és az egyik végén több érték van, mint a másikon. Az eloszlás alakját fontos szem előtt tartani, mert csak néhány leíró statisztikát kell használni ferde eloszlásokkal.
a szélsőséges kiugró értékek félrevezető statisztikákat is készíthetnek, ezért szükség lehet szisztematikus megközelítésre ezen értékek kezeléséhez.
Számítsa ki a központi tendencia mértékét
a központi tendencia mértéke leírja, hogy az adathalmaz legtöbb értéke hol fekszik. A központi tendencia három fő mérését gyakran jelentik:
- mód: az adatkészlet legnépszerűbb válasza vagy értéke.
- medián: az érték a pontos közepén az adathalmaz, ha megrendelt alacsony a magas.
- átlag: az összes érték összege osztva az értékek számával.
az eloszlás alakjától és a mérési szinttől függően azonban ezek közül csak egy vagy kettő lehet megfelelő. Például sok demográfiai jellemző csak az üzemmód vagy az arányok felhasználásával írható le, míg egy változóhoz hasonló reakcióidőnek egyáltalán nincs módja.
Számítsa ki a változékonyság mértékét
a változékonyság mértéke megmondja, hogy az adathalmaz értékei hogyan oszlanak el. A változékonyság négy fő mérését gyakran jelentik:
- tartomány: a legmagasabb érték mínusz az adatkészlet legalacsonyabb értéke.
- interkvartilis tartomány: az adatkészlet középső felének tartománya.
- szórás: az adathalmaz egyes értékei és az átlag közötti átlagos távolság.
- variancia: a szórás négyzete.
ismét az eloszlás alakjának és a mérési szintnek kell irányítania a variabilitási statisztikák kiválasztását. Az interkvartilis tartomány a legjobb mértékegység a ferde eloszlásokhoz, míg a szórás és a szórás a legjobb információt nyújtja a normál eloszlásokhoz.
- kísérleti
- korrelációs
a táblázat segítségével ellenőrizze, hogy a leíró statisztikák egységei összehasonlíthatók-e a pretest és a posttest pontszámokkal. Például a varianciaszintek hasonlóak a csoportok között? Vannak szélsőséges értékek? Ha vannak, előfordulhat, hogy a statisztikai teszt elvégzése előtt azonosítania kell és el kell távolítania az extrém kiugró értékeket az adatkészletből, vagy át kell alakítania az adatokat.
| Pretest eredmények | Posttest eredmények | |
|---|---|---|
| átlag | 68.44 | 75.25 |
| szórás | 9.43 | 9.88 |
| variancia | 88.96 | 97.96 |
| tartomány | 36.25 | 45.12 |
| N | 30 | |
ebből a táblázatból láthatjuk, hogy az átlagos pontszám a meditációs gyakorlat után nőtt, és a két pontszám eltérései összehasonlíthatók. Ezután statisztikai tesztet végezhetünk annak kiderítésére, hogy a teszteredmények ezen javulása statisztikailag szignifikáns-e a populációban.
fontos ellenőrizni, hogy az adatpontok széles skálája van-e. Ha nem, akkor az adatok bizonyos csoportok felé torzulhatnak, mint mások (pl. magas tanulmányi teljesítményűek), és csak korlátozott következtetéseket lehet levonni egy kapcsolatról.
| szülői jövedelem (USD) | GPA | |
|---|---|---|
| átlag | 62,100 | 3.12 |
| szórás | 15,000 | 0.45 |
| variancia | 225,000,000 | 0.16 |
| tartomány | 8,000–378,000 | 2.64–4.00 |
| N | 653 | |
ezután kiszámolhatunk egy korrelációs együtthatót, és statisztikai tesztet végezhetünk, hogy megértsük a változók közötti kapcsolat jelentőségét a populációban.
4. lépés: Tesztelje a hipotéziseket, vagy végezzen becsléseket következtetési statisztikákkal
a mintát leíró számot statisztikának, míg a populációt leíró számot paraméternek nevezzük. A következtetési statisztikák segítségével következtetéseket vonhat le a populációs paraméterekről a mintastatisztikák alapján.
a kutatók gyakran két fő módszert alkalmaznak (egyszerre) a statisztikák következtetéseinek levonására.
- becslés: a populációs paraméterek kiszámítása minta statisztikák alapján.
- hipotézis tesztelés: formális folyamat a populációval kapcsolatos kutatási előrejelzések tesztelésére minták felhasználásával.
becslés
a mintastatisztikákból kétféle becslést készíthet a populációs paraméterekről:
- pontbecslés: olyan érték, amely a pontos paraméter legjobb becslését képviseli.
- intervallumbecslés: olyan értéktartomány, amely a lehető legjobban meghatározza a paraméter helyét.
ha a cél az, hogy a mintaadatokból következtetéseket vonjon le és jelentse a populációs jellemzőket, akkor a legjobb, ha mind a pont -, mind az intervallumbecsléseket használja a papírban.
a mintastatisztikát a populációs paraméter pontbecslésének tekintheti, ha reprezentatív mintája van (például egy széles közvélemény-kutatásban a jelenlegi kormányt támogató minta arányát vesszük a kormány támogatóinak népességarányaként).
mindig hiba van a becslésben, ezért meg kell adnia egy konfidencia intervallumot intervallum becslésként, hogy megmutassa a pontbecslés körüli változékonyságot.
a konfidencia intervallum a standard hibát és a normál normál eloszlás z pontszámát használja annak közvetítésére, hogy általában hol találja meg a populációs paramétert az idő nagy részében.
hipotézis tesztelés
egy minta adatainak felhasználásával tesztelheti a populációban lévő változók közötti kapcsolatokra vonatkozó hipotéziseket. A hipotézis tesztelése azzal a feltevéssel kezdődik, hogy a nullhipotézis igaz a populációban, és statisztikai teszteket használ annak felmérésére, hogy a nullhipotézis elutasítható-e vagy sem.
a statisztikai tesztek meghatározzák, hogy a mintaadatok hol fekszenek a mintaadatok várható eloszlásán, ha a nullhipotézis igaz lenne. Ezek a tesztek két fő kimenetet adnak:
- a tesztstatisztika megmutatja, hogy az adatok mennyiben különböznek a teszt nullhipotézisétől.
- a p érték megmutatja az eredmények megszerzésének valószínűségét, ha a nullhipotézis valóban igaz a populációban.
a statisztikai vizsgálatok három fő fajtából állnak:
- az összehasonlító tesztek felmérik az eredmények csoportbeli különbségeit.
- a regressziós tesztek a változók közötti ok-okozati összefüggéseket értékelik.
- a korrelációs tesztek az okozati összefüggés feltételezése nélkül értékelik a változók közötti kapcsolatokat.
a statisztikai teszt választása a kutatási kérdésektől, a kutatási tervezéstől, a mintavételi módszertől és az adatjellemzőktől függ.
parametrikus tesztek
a Parametrikus tesztek a mintaadatok alapján erőteljes következtetéseket vonnak le a populációról. De ahhoz, hogy használhassuk őket, bizonyos feltételezéseknek teljesülniük kell, és csak bizonyos típusú változókat lehet használni. Ha adatai megsértik ezeket a feltételezéseket, elvégezheti a megfelelő adatátalakításokat, vagy alternatív, nem paraméteres teszteket használhat.
a regresszió modellezi, hogy a prediktor változó változásai milyen mértékben eredményezik az eredményváltozó(k) változását.
- egy egyszerű lineáris regresszió egy prediktor változót és egy eredményváltozót tartalmaz.
- a többszörös lineáris regresszió két vagy több prediktor változót és egy eredményváltozót tartalmaz.
az összehasonlító tesztek általában összehasonlítják a csoportok eszközeit. Ezek lehetnek a mintán belüli különböző csoportok eszközei (pl. kezelési és kontrollcsoport), egy különböző időpontban vett mintacsoport átlagai (pl. pretest és posttest pontszámok), vagy a minta átlaga és a populáció átlaga.
- a t-teszt pontosan 1 vagy 2 csoportra vonatkozik, ha a minta kicsi (30 vagy kevesebb).
- A z teszt pontosan 1 vagy 2 csoportra vonatkozik, ha a minta Nagy.
- az ANOVA 3 vagy több csoportra vonatkozik.
A z és t teszteknek altípusai vannak a Minták száma és típusa, valamint a hipotézisek alapján:
- ha csak egy mintája van, amelyet össze szeretne hasonlítani egy populációs átlaggal, használjon egymintás tesztet.
- ha párosított mérésekkel rendelkezik (alanyon belüli tervezés), használjon függő (párosított) mintatesztet.
- ha teljesen különálló méréseket végez két páratlan csoporttól (az alanyok közötti tervezés), használjon független mintatesztet.
- ha egy adott irányban különbséget vár a csoportok között, használjon egyfarkú tesztet.
- ha nincs elvárása a csoportok közötti különbség irányával kapcsolatban, használjon Kétfarkú tesztet.
az egyetlen paraméteres korrelációs teszt Pearson r. a korrelációs együttható (r) megmondja a két kvantitatív változó közötti lineáris kapcsolat erősségét.
annak teszteléséhez azonban, hogy a mintában a korreláció elég erős-e ahhoz, hogy fontos legyen a populációban, el kell végeznie a korrelációs együttható szignifikancia tesztjét is, általában a t teszt, hogy p értéket kapjunk. Ez a teszt a minta méretét használja annak kiszámításához, hogy a korrelációs együttható mennyiben különbözik a nullától a populációban.
- kísérleti
- korrelációs
függő mintákat, egyfarkú t tesztet használ annak felmérésére, hogy a meditációs gyakorlat jelentősen javította-e a matematikai teszt pontszámait. A teszt megadja:
- a T érték (vizsgálati statisztika) 3,00
- a p értéke 0.0028
bár Pearson r egy tesztstatisztika, nem mond semmit arról, hogy a korreláció mennyire jelentős a populációban. Azt is meg kell vizsgálnia, hogy ez a minta korrelációs együttható elég nagy-e ahhoz, hogy bizonyítsa a korrelációt a populációban.
A t-teszt azt is meghatározhatja, hogy a korrelációs együttható mennyire különbözik a nullától a minta mérete alapján. Mivel pozitív korrelációt vár a szülői jövedelem és a GPA között, egymintás, egyfarkú t tesztet használ. A T teszt megadja:
- a t értéke 3,08
- a p értéke 0.001
5. lépés: Az eredmények értelmezése
a statisztikai elemzés utolsó lépése az eredmények értelmezése.
statisztikai szignifikancia
a hipotézisvizsgálatban a statisztikai szignifikancia a következtetések kialakításának fő kritériuma. Összehasonlítja a p értékét egy meghatározott szignifikancia szinttel (általában 0,05) annak eldöntéséhez, hogy az eredmények statisztikailag szignifikánsak vagy nem szignifikánsak-e.
a statisztikailag szignifikáns eredmények valószínűleg nem kizárólag a véletlen miatt merültek fel. Csak nagyon alacsony az esélye egy ilyen eredménynek, ha a nullhipotézis igaz a populációban.
- kísérleti
- korrelációs
ez azt jelenti, hogy úgy gondolja, hogy a meditációs beavatkozás, nem pedig véletlenszerű tényezők, közvetlenül okozta a teszt pontszámok növekedését.
vegye figyelembe, hogy a korreláció nem mindig jelent Ok-okozati összefüggést, mert gyakran sok mögöttes tényező járul hozzá egy olyan komplex változóhoz, mint a GPA. Még akkor is, ha az egyik változó kapcsolódik a másikhoz, ennek oka lehet egy harmadik változó, amely mindkettőt befolyásolja, vagy közvetett kapcsolatok a két változó között.
a nagy mintaméret erősen befolyásolhatja a korrelációs együttható statisztikai szignifikanciáját azáltal, hogy a nagyon kicsi korrelációs együtthatók szignifikánsnak tűnnek.
Hatásméret
a statisztikailag szignifikáns eredmény nem feltétlenül jelenti azt, hogy a megállapításhoz fontos valós alkalmazások vagy klinikai eredmények vannak.
ezzel szemben a hatásméret jelzi az eredmények gyakorlati jelentőségét. Fontos, hogy jelentse a hatásméreteket a következtetési statisztikákkal együtt, hogy teljes képet kapjon az eredményekről. Jelentenie kell a hatásméretek intervallumbecsléseit is, ha APA stílusú papírt ír.
- kísérleti
- korrelációs
Cohen d értéke 0.72, közepes vagy nagy gyakorlati jelentősége van annak a megállapításnak, hogy a meditációs gyakorlat javította a teszt pontszámokat.
mivel az érték 0,1 és 0,3 között van, a szülői jövedelem és a GPA közötti kapcsolat megállapítása nagyon kicsi hatást jelent, és korlátozott gyakorlati jelentőséggel bír.
döntési hibák
az I. és II.típusú hibák a kutatási következtetések során elkövetett hibák. Az I. típusú hiba a nullhipotézis elutasítását jelenti, amikor az valójában igaz, míg a II.típusú hiba azt jelenti, hogy nem utasítják el a nullhipotézist, ha hamis.
az optimális szignifikancia szint kiválasztásával és a nagy teljesítmény biztosításával törekedhet a hibák kockázatának minimalizálására. A két hiba között azonban kompromisszum van, ezért finom egyensúlyra van szükség.
Frequentist versus Bayes statisztika
hagyományosan a frequentist statisztika hangsúlyozza a nullhipotézis szignifikancia tesztelését, és mindig egy valódi nullhipotézis feltételezésével kezdődik.
a bayesi statisztikák azonban alternatív megközelítésként népszerűvé váltak az elmúlt évtizedekben. Ebben a megközelítésben a korábbi kutatásokat arra használja, hogy folyamatosan frissítse hipotéziseit elvárásai és megfigyelései alapján.
a Bayes-faktor összehasonlítja a nullra vonatkozó bizonyítékok relatív erősségét az alternatív hipotézissel szemben, ahelyett, hogy következtetést vonna le a nullhipotézis elutasításáról vagy sem.
Gyakran Ismételt Kérdések a statisztikai elemzésről
a statisztikai elemzés a kvantitatív kutatási adatok elemzésének fő módszere. Valószínűségeket és modelleket használ, hogy tesztelje a populációra vonatkozó előrejelzéseket a mintaadatokból.
leíró statisztikák összefoglalják az adathalmaz jellemzőit. A következtetési statisztikák lehetővé teszik egy hipotézis tesztelését vagy annak felmérését, hogy adatai általánosíthatók-e a szélesebb populációra.
a hipotézisvizsgálat egy hivatalos eljárás a világról alkotott elképzeléseink statisztikai felhasználásával történő vizsgálatára. A tudósok arra használják, hogy teszteljék a konkrét előrejelzéseket, az úgynevezett hipotéziseket, kiszámítva, hogy mennyire valószínű, hogy a változók közötti minta vagy kapcsolat véletlenül keletkezhetett.
ban ben statisztikai hipotézis tesztelés, a teszt nullhipotézise mindig nem jósol hatást vagy összefüggést a változók között, míg az alternatív hipotézis kimondja a hatás vagy kapcsolat kutatási előrejelzését.
a statisztikai szignifikancia egy olyan kifejezés, amelyet a kutatók arra használnak, hogy kijelentsék, hogy nem valószínű, hogy megfigyeléseik statisztikai teszt nullhipotézise alapján történhettek volna. A szignifikanciát általában a p-érték, vagy valószínűségi érték.
a statisztikai szignifikancia önkényes – a kutató által választott küszöbértéktől vagy alfa értéktől függ. A leggyakoribb küszöb p < 0,05, ami azt jelenti, hogy az adatok valószínűleg a nullhipotézis alatt az idő kevesebb mint 5% – ában fordulnak elő.
amikor a p-érték a választott alfa érték alá esik, akkor azt mondjuk, hogy a teszt eredménye statisztikailag szignifikáns.