statistisk analys innebär att undersöka trender, mönster och relationer med hjälp av kvantitativa data. Det är ett viktigt forskningsverktyg som används av forskare, regeringar, företag och andra organisationer.
för att dra giltiga slutsatser kräver statistisk analys noggrann planering från början av forskningsprocessen. Du måste ange dina hypoteser och fatta beslut om din forskningsdesign, provstorlek och provtagningsförfarande.
när du har samlat in data från ditt prov kan du organisera och sammanfatta data med beskrivande statistik. Sedan kan du använda inferentiell statistik för att formellt testa hypoteser och göra uppskattningar om befolkningen. Slutligen kan du tolka och generalisera dina resultat.
denna artikel är en praktisk introduktion till statistisk analys för studenter och forskare. Vi går igenom stegen med två forskningsexempel. Den första undersöker en potentiell orsak-och-effekt-relation, medan den andra undersöker en potentiell korrelation mellan variabler.
Steg 1: Skriv dina hypoteser och planera din forskningsdesign
för att samla in giltiga data för statistisk analys måste du först ange dina hypoteser och planera din forskningsdesign.
skriva statistiska hypoteser
målet med forskning är ofta att undersöka ett samband mellan variabler inom en population. Du börjar med en förutsägelse och använder statistisk analys för att testa den förutsägelsen.
en statistisk hypotes är ett formellt sätt att skriva en förutsägelse om en befolkning. Varje forskningsprediktion omformuleras till null och alternativa hypoteser som kan testas med hjälp av provdata.
medan nollhypotesen alltid förutsäger ingen effekt eller inget samband mellan variabler, anger den alternativa hypotesen din forskningsprognos av en effekt eller ett förhållande.
- nollhypotes: en 5-minuters meditationsövning har ingen effekt på matematiska testresultat hos tonåringar.
- alternativ hypotes: en 5-minuters meditationsövning kommer att förbättra matteprovresultat hos tonåringar.
- nollhypotes: föräldrainkomst och GPA har inget samband med varandra hos studenter.
- alternativ hypotes: föräldrainkomst och GPA är positivt korrelerade hos studenter.
planera din forskningsdesign
en forskningsdesign är din övergripande strategi för datainsamling och analys. Det bestämmer de statistiska tester du kan använda för att testa din hypotes senare.
bestäm först om din forskning kommer att använda en beskrivande, korrelationell eller experimentell design. Experiment påverkar direkt variabler, medan beskrivande och korrelationsstudier endast mäter variabler.
- i en experimentell design kan du bedöma ett orsak-och-effekt-förhållande (t.ex. effekten av meditation på testresultat) med hjälp av statistiska test av jämförelse eller regression.
- i en korrelationsdesign kan du utforska relationer mellan variabler (t. ex., föräldrainkomst och GPA) utan något antagande om orsakssamband med hjälp av korrelationskoefficienter och signifikanstester.
- i en beskrivande design kan du studera egenskaperna hos en befolkning eller ett fenomen (t.ex. förekomsten av ångest hos amerikanska studenter) med hjälp av statistiska tester för att dra slutsatser från provdata.
din forskningsdesign gäller också om du ska jämföra deltagare på gruppnivå eller individnivå, eller båda.
- i en design mellan ämnen jämför du resultaten på gruppnivå för deltagare som har utsatts för olika behandlingar (t.ex. de som utförde en meditationsövning jämfört med de som inte gjorde det).
- i en design inom ämnen jämför du upprepade åtgärder från deltagare som har deltagit i alla behandlingar av en studie (t.ex. poäng från före och efter att ha utfört en meditationsövning).
- Experimentell
- Korrelation
först tar du baseline testresultat från deltagarna. Därefter kommer dina deltagare att genomgå en 5-minuters meditationsövning. Slutligen registrerar du deltagarnas poäng från ett andra matteprov.
i detta experiment är den oberoende variabeln 5-minuters meditationsövning, och den beroende variabeln är förändringen i matteprovresultat från före och efter interventionen.
det finns inga beroende eller oberoende variabler i denna studie, eftersom du bara vill mäta variabler utan att påverka dem på något sätt.
Mätvariabler
när du planerar en forskningsdesign bör du operationalisera dina variabler och bestämma exakt hur du ska mäta dem.
för statistisk analys är det viktigt att överväga mätnivån för dina variabler, som berättar vilken typ av data de innehåller:
- kategoriska data representerar grupperingar. Dessa kan vara nominella (t. ex., kön) eller ordinär (t.ex. nivå av språkförmåga).
- kvantitativa data representerar mängder. Dessa kan vara på en intervallskala (t.ex. testresultat) eller en förhållandeskala (t. ex. Ålder).
många variabler kan mätas med olika precisionsnivåer. Till exempel kan åldersdata vara kvantitativa (8 år) eller kategoriska (unga). Om en variabel kodas numeriskt (t.ex. nivå av överenskommelse från 1-5) betyder det inte automatiskt att det är kvantitativt istället för kategoriskt.
att identifiera mätnivån är viktigt för att välja lämplig statistik och hypotesprov. Du kan till exempel beräkna ett medelvärde med kvantitativa data, men inte med kategoriska data.
i en forskningsstudie, tillsammans med mått på dina variabler av intresse, samlar du ofta in data om relevanta deltagaregenskaper.
- Experimentell
- Korrelation
| variabel | typ av data |
|---|---|
| ålder | kvantitativ (förhållande) |
| kön | kategorisk (nominell) |
| ras eller etnicitet | kategorisk (nominell) |
| Baseline testresultat | kvantitativ (intervall) |
| slutliga testresultat | kvantitativ (intervall) |
| variabel | typ av data |
|---|---|
| föräldrainkomst | kvantitativ (förhållande) |
| GPA | kvantitativ (intervall) |
steg 2: Samla in data från ett prov
i de flesta fall är det för svårt eller dyrt att samla in data från varje medlem av befolkningen du är intresserad av att studera. Istället samlar du in data från ett prov.
statistisk analys låter dig tillämpa dina resultat utöver ditt eget prov så länge du använder lämpliga provtagningsförfaranden. Du bör sträva efter ett prov som är representativt för befolkningen.
provtagning för statistisk analys
det finns två huvudmetoder för att välja ett prov.
- sannolikhetsprovtagning: varje medlem av befolkningen har en chans att väljas för studien genom slumpmässigt urval.
- icke-sannolikhetsprovtagning: vissa medlemmar av befolkningen är mer benägna än andra att väljas för studien på grund av kriterier som bekvämlighet eller frivilligt självval.
i teorin, för mycket generaliserbara fynd, bör du använda en sannolikhetsprovtagningsmetod. Slumpmässigt urval minskar provtagningsförspänning och säkerställer att data från ditt prov faktiskt är typiskt för befolkningen. Parametriska tester kan användas för att göra starka statistiska slutsatser när data samlas in med hjälp av sannolikhetsprovtagning.
men i praktiken är det sällan möjligt att samla det perfekta provet. Medan icke-sannolikhetsprover är mer benägna att vara partiska, är de mycket lättare att rekrytera och samla in data från. Icke-parametriska tester är mer lämpliga för icke-sannolikhetsprover, men de resulterar i svagare slutsatser om befolkningen.
om du vill använda parametriska tester för icke-sannolikhetsprover måste du göra så:
- ditt prov är representativt för den befolkning du generaliserar dina resultat till.
- ditt prov saknar systematisk bias.
Tänk på att extern validitet innebär att du bara kan generalisera dina slutsatser till andra som delar egenskaperna hos ditt prov. Till exempel resultat från västerländska, utbildade, industrialiserade, rika och Demokratiska prover (t. ex., studenter i USA) är inte automatiskt tillämpliga på alla icke-konstiga populationer.
om du tillämpar parametriska tester på data från icke-sannolikhetsprover, var noga med att utarbeta begränsningarna för hur långt dina resultat kan generaliseras i din diskussionsavdelning.
skapa ett lämpligt provtagningsförfarande
baserat på de resurser som finns tillgängliga för din forskning, bestäm hur du ska rekrytera deltagare.
- kommer du att ha resurser för att annonsera din studie i stor utsträckning, inklusive utanför din universitetsinställning?
- har du möjlighet att rekrytera ett mångsidigt urval som representerar en bred befolkning?
- har du tid att kontakta och följa upp med medlemmar i svåråtkomliga grupper?
- experimentell
- korrelation
dina deltagare är självvalda av sina skolor. Även om du använder ett icke-sannolikhetsprov, strävar du efter ett mångsidigt och representativt prov.
dina deltagare frivilligt för undersökningen, vilket gör detta till ett icke-sannolikhetsprov.
beräkna tillräcklig provstorlek
innan du rekryterar deltagare, Bestäm din provstorlek antingen genom att titta på andra studier inom ditt område eller använda statistik. Ett prov som är för litet kan vara representativt för provet, medan ett prov som är för stort blir dyrare än nödvändigt.
det finns många provstorleksräknare online. Olika formler används beroende på om du har undergrupper eller hur rigorös din studie ska vara (t.ex. i klinisk forskning). Som tumregel är minst 30 enheter eller mer per undergrupp nödvändig.
för att använda dessa räknare måste du förstå och mata in dessa nyckelkomponenter:
- signifikansnivå (alfa): risken att avvisa en sann nollhypotes som du är villig att ta, vanligtvis inställd på 5%.
- statistisk effekt: sannolikheten för att din studie upptäcker en effekt av en viss storlek om det finns en, vanligtvis 80% eller högre.
- förväntad effekt storlek: en standardiserad indikation på hur stort det förväntade resultatet av din studie kommer att vara, vanligtvis baserat på andra liknande studier.
- Population standardavvikelse: en uppskattning av populationsparametern baserat på en tidigare studie eller en egen pilotstudie.

steg 3: sammanfatta dina data med beskrivande statistik
när du har samlat in alla dina data kan du inspektera dem och beräkna beskrivande statistik som sammanfattar dem.
inspektera dina data
det finns olika sätt att inspektera dina data, inklusive följande:
- organisera data från varje variabel i frekvensfördelningstabeller.
- visar data från en nyckelvariabel i ett stapeldiagram för att visa fördelningen av svar.
- visualisera förhållandet mellan två variabler med hjälp av en scatter-plot.
genom att visualisera dina data i tabeller och diagram kan du bedöma om dina data följer en skev eller normalfördelning och om det finns några avvikelser eller saknade data.
en normalfördelning innebär att dina data är symmetriskt fördelade runt ett centrum där de flesta värden ligger, med värdena avsmalnande vid svansändarna.
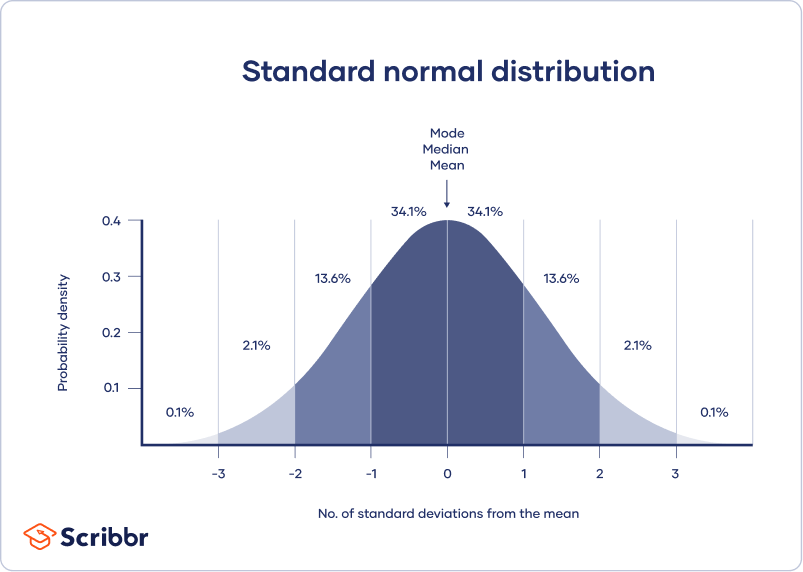
däremot är en skev fördelning asymmetrisk och har fler värden i ena änden än den andra. Formen på fördelningen är viktigt att tänka på eftersom endast en del beskrivande statistik bör användas med skeva fördelningar.
extrema avvikare kan också producera vilseledande statistik, så du kan behöva ett systematiskt tillvägagångssätt för att hantera dessa värden.
beräkna mått på central tendens
mått på central tendens beskriver var de flesta värdena i en datamängd ligger. Tre huvudmått av central tendens rapporteras ofta:
- läge: det mest populära svaret eller värdet i datamängden.
- Median: värdet i den exakta mitten av datamängden när den beställs från låg till hög.
- medelvärde: summan av alla värden dividerat med antalet värden.
beroende på formen på fördelningen och mätnivån kan dock endast en eller två av dessa åtgärder vara lämpliga. Till exempel kan många demografiska egenskaper endast beskrivas med läget eller proportionerna, medan en variabel som reaktionstid kanske inte har ett läge alls.
beräkna mått på variabilitet
mått på variabilitet berätta hur spridda värdena i en datamängd är. Fyra huvudsakliga mått på variabilitet rapporteras ofta:
- intervall: Det högsta värdet minus det lägsta värdet för datamängden.
- Interkvartilintervall: intervallet för den mellersta halvan av datamängden.
- standardavvikelse: det genomsnittliga avståndet mellan varje värde i din datamängd och medelvärdet.
- varians: kvadraten på standardavvikelsen.
återigen bör formen på fördelningen och mätnivån styra ditt val av variabilitetsstatistik. Interkvartilintervallet är det bästa måttet för skeva fördelningar, medan standardavvikelse och varians ger den bästa informationen för normala fördelningar.
- experimentell
- korrelation
med ditt bord bör du kontrollera om enheterna i den beskrivande statistiken är jämförbara för pretest-och posttest-poäng. Till exempel är variansnivåerna lika mellan grupperna? Finns det några extrema värden? Om det finns kan du behöva identifiera och ta bort extrema avvikare i din datamängd eller omvandla dina data innan du utför ett statistiskt test.
| förtest resultat | posttest resultat | |
|---|---|---|
| medelvärde | 68.44 | 75.25 |
| standardavvikelse | 9.43 | 9.88 |
| varians | 88.96 | 97.96 |
| räckvidd | 36.25 | 45.12 |
| N | 30 | |
från denna tabell kan vi se att medelvärdet ökade efter meditationsövningen, och variationerna i de två poängen är jämförbara. Därefter kan vi utföra ett statistiskt test för att ta reda på om denna förbättring av testresultaten är statistiskt signifikant i befolkningen.
det är viktigt att kontrollera om du har ett brett utbud av datapunkter. Om du inte gör det kan dina uppgifter Skevas mot vissa grupper mer än andra (t.ex. höga akademiska prestationer), och endast begränsade slutsatser kan göras om ett förhållande.
| föräldrainkomst (USD) | GPA | |
|---|---|---|
| medelvärde | 62,100 | 3.12 |
| standardavvikelse | 15,000 | 0.45 |
| varians | 225,000,000 | 0.16 |
| räckvidd | 8,000–378,000 | 2.64–4.00 |
| N | 653 | |
därefter kan vi beräkna en korrelationskoefficient och utföra ett statistiskt test för att förstå betydelsen av förhållandet mellan variablerna i befolkningen.
steg 4: Testa hypoteser eller gör uppskattningar med inferentiell statistik
ett tal som beskriver ett prov kallas en statistik, medan ett tal som beskriver en befolkning kallas en parameter. Med hjälp av inferentiell statistik kan du dra slutsatser om befolkningsparametrar baserat på provstatistik.
forskare använder ofta två huvudmetoder (samtidigt) för att dra slutsatser i statistiken.
- uppskattning: beräkning av populationsparametrar baserat på provstatistik.
- hypotesprövning: en formell process för att testa forskningsprognoser om befolkningen med hjälp av prover.
uppskattning
du kan göra två typer av uppskattningar av befolkningsparametrar från provstatistik:
- en punktuppskattning: ett värde som representerar din bästa gissning av den exakta parametern.
- en intervalluppskattning: ett intervall av värden som representerar din bästa gissning om var parametern ligger.
om ditt mål är att härleda och rapportera befolkningsegenskaper från provdata är det bäst att använda både punkt-och intervalluppskattningar i ditt papper.
du kan betrakta en provstatistik som en punktuppskattning för befolkningsparametern när du har ett representativt urval (t.ex. i en bred opinionsundersökning tas andelen av ett urval som stöder den nuvarande regeringen som befolkningsandelen av regeringsstödjare).
det finns alltid fel i uppskattningen, så du bör också ge ett konfidensintervall som en intervalluppskattning för att visa variationen kring en punktuppskattning.
ett konfidensintervall använder standardfelet och z-poängen från standard normalfördelning för att förmedla var du vanligtvis förväntar dig att hitta populationsparametern för det mesta.
hypotesprovning
med hjälp av data från ett prov kan du testa hypoteser om förhållanden mellan variabler i befolkningen. Hypotesprovning börjar med antagandet att nollhypotesen är sant i befolkningen, och du använder statistiska tester för att bedöma om nollhypotesen kan avvisas eller inte.
statistiska tester bestämmer var dina provdata skulle ligga på en förväntad fördelning av provdata om nollhypotesen var sann. Dessa tester ger två huvudutgångar:
- en teststatistik berättar hur mycket dina data skiljer sig från testets nollhypotes.
- ett p-värde berättar sannolikheten för att få dina resultat om nollhypotesen faktiskt är sant i befolkningen.
statistiska tester finns i tre huvudvarianter:
- jämförelsetester bedömer gruppskillnader i resultat.
- regressionstester bedömer orsak-och-effekt-samband mellan variabler.
- Korrelationstester bedömer förhållanden mellan variabler utan att anta orsakssamband.
ditt val av statistiskt test beror på dina forskningsfrågor, forskningsdesign, provtagningsmetod och dataegenskaper.
parametriska tester
parametriska tester gör kraftfulla slutsatser om befolkningen baserat på provdata. Men för att använda dem måste vissa antaganden uppfyllas, och endast vissa typer av variabler kan användas. Om dina data bryter mot dessa antaganden kan du utföra lämpliga datatransformationer eller använda alternativa icke-parametriska tester istället.
en regressionsmodeller i vilken utsträckning förändringar i en prediktorvariabel resulterar i förändringar i resultatvariabel(er).
- en enkel linjär regression innehåller en prediktorvariabel och en resultatvariabel.
- en multipel linjär regression innehåller två eller flera prediktorvariabler och en resultatvariabel.
jämförelsetester jämför vanligtvis medel för grupper. Dessa kan vara medel för olika grupper inom ett prov (t.ex. en behandlings-och kontrollgrupp), medel för en provgrupp som tas vid olika tidpunkter (t. ex. pretest-och posttest-poäng) eller ett provmedelvärde och ett populationsmedel.
- ett T-test är för exakt 1 eller 2 grupper när provet är litet (30 eller mindre).
- ett z-test är för exakt 1 eller 2 grupper när provet är stort.
- en ANOVA är för 3 eller fler grupper.
Z-och t-testerna har undertyper baserade på antal och typer av prover och hypoteserna:
- om du bara har ett prov som du vill jämföra med ett populationsmedel, använd ett provprov.
- om du har parade mätningar (design inom ämnen), använd ett beroende (parat) provtest.
- om du har helt separata mätningar från två oöverträffade grupper (Design mellan ämnen), använd ett oberoende provtest.
- om du förväntar dig en skillnad mellan grupper i en viss riktning, Använd ett ensidigt test.
- om du inte har några förväntningar på riktningen för en skillnad mellan grupper, använd ett två-tailed test.
det enda parametriska korrelationstestet är Pearsons r. korrelationskoefficienten (r) berättar styrkan i ett linjärt förhållande mellan två kvantitativa variabler.
men för att testa om korrelationen i provet är tillräckligt stark för att vara viktig i befolkningen måste du också utföra ett signifikanstest av korrelationskoefficienten, vanligtvis ett T-test, för att få ett p-värde. Detta test använder din provstorlek för att beräkna hur mycket korrelationskoefficienten skiljer sig från noll i befolkningen.
- experimentell
- korrelation
du använder ett beroende-prov, en-tailed t-test för att bedöma om meditationsövningen signifikant förbättrade matteprovresultat. Testet ger dig:
- ett T-värde (teststatistik) på 3,00
- ett p-värde på 0.0028
även om Pearsons r är en teststatistik, berättar den ingenting om hur signifikant korrelationen är i befolkningen. Du måste också testa om denna provkorrelationskoefficient är tillräckligt stor för att visa en korrelation i befolkningen.
ett T-test kan också bestämma hur signifikant en korrelationskoefficient skiljer sig från noll baserat på provstorlek. Eftersom du förväntar dig en positiv korrelation mellan föräldrainkomst och GPA, använder du ett prov, en-tailed t-test. T-testet ger dig:
- ett t-värde på 3,08
- ett p-värde på 0.001
Steg 5: Tolka dina resultat
det sista steget i statistisk analys är att tolka dina resultat.
statistisk signifikans
i hypotesprovning är statistisk signifikans de viktigaste kriterierna för att bilda slutsatser. Du jämför ditt p-värde med en inställd signifikansnivå (vanligtvis 0,05) för att avgöra om dina resultat är statistiskt signifikanta eller icke-signifikanta.
statistiskt signifikanta resultat anses osannolikt ha uppstått enbart på grund av slump. Det finns bara en mycket låg chans att ett sådant resultat inträffar om nollhypotesen är sant i befolkningen.
- experimentell
- korrelation
det betyder att du tror att meditationsinterventionen, snarare än slumpmässiga faktorer, direkt orsakade ökningen av testresultat.
Observera att korrelation inte alltid betyder orsakssamband, eftersom det ofta finns många underliggande faktorer som bidrar till en komplex variabel som GPA. Även om en variabel är relaterad till en annan kan detta bero på att en tredje variabel påverkar dem båda eller indirekta länkar mellan de två variablerna.
en stor provstorlek kan också starkt påverka den statistiska betydelsen av en korrelationskoefficient genom att göra mycket små korrelationskoefficienter verkar betydande.
effektstorlek
ett statistiskt signifikant resultat betyder inte nödvändigtvis att det finns viktiga verkliga applikationer eller kliniska resultat för ett resultat.
däremot indikerar effektstorleken den praktiska betydelsen av dina resultat. Det är viktigt att rapportera effektstorlekar tillsammans med din inferentiella statistik för en fullständig bild av dina resultat. Du bör också rapportera intervalluppskattningar av effektstorlekar om du skriver ett APA-stilpapper.
- experimentell
- korrelation
med en Cohens d av 0.72, det finns medelhög till hög praktisk betydelse för ditt konstaterande att meditationsövningen förbättrade testresultat.
eftersom ditt värde är mellan 0,1 och 0,3 representerar din upptäckt av ett förhållande mellan föräldrainkomst och GPA en mycket liten effekt och har begränsad praktisk betydelse.
Beslutsfel
typ i-och typ II-fel är misstag som görs i forskningsslutsatser. Ett typ i-fel innebär att man avvisar nollhypotesen när det faktiskt är sant, medan ett typ II-fel innebär att man inte avvisar nollhypotesen när den är falsk.
du kan sikta på att minimera risken för dessa fel genom att välja en optimal signifikansnivå och säkerställa hög effekt. Det finns dock en avvägning mellan de två felen, så en fin balans är nödvändig.
Frequentist kontra Bayesian statistik
traditionellt betonar frequentist statistik nollhypotes signifikanstestning och börjar alltid med antagandet om en sann nollhypotes.
Bayesiansk statistik har dock vuxit i popularitet som ett alternativt tillvägagångssätt under de senaste decennierna. I detta tillvägagångssätt använder du tidigare forskning för att kontinuerligt uppdatera dina hypoteser baserat på dina förväntningar och observationer.
Bayes factor jämför den relativa styrkan av bevis för noll kontra den alternativa hypotesen snarare än att göra en slutsats om att avvisa nollhypotesen eller inte.
Vanliga frågor om statistisk analys
statistisk analys är den huvudsakliga metoden för att analysera kvantitativa forskningsdata. Den använder sannolikheter och modeller för att testa förutsägelser om en population från provdata.
beskrivande statistik sammanfattar egenskaperna hos en datamängd. Inferentiell statistik låter dig testa en hypotes eller bedöma om dina data är generaliserbara för den bredare befolkningen.
hypotesprovning är ett formellt förfarande för att undersöka våra tankar om världen med hjälp av statistik. Det används av forskare för att testa specifika förutsägelser, kallade hypoteser, genom att beräkna hur sannolikt det är att ett mönster eller förhållande mellan variabler kunde ha uppstått av en slump.
i statistisk hypotesprovning förutsäger nollhypotesen för ett test alltid ingen effekt eller inget samband mellan variabler, medan den alternativa hypotesen anger din forskningsprognos av en effekt eller relation.
statistisk signifikans är en term som används av forskare för att konstatera att det är osannolikt att deras observationer kunde ha inträffat under nollhypotesen för ett statistiskt test. Betydelse betecknas vanligtvis med ett p-värde eller sannolikhetsvärde.
statistisk signifikans är godtycklig – det beror på tröskeln, eller alfavärdet, valt av forskaren. Den vanligaste tröskeln är p < 0,05, vilket innebär att data sannolikt kommer att inträffa mindre än 5% av tiden under nollhypotesen.
när p-värdet faller under det valda alfavärdet, säger vi att resultatet av testet är statistiskt signifikant.